2007年10月30日
2007年10月26日
About Nutch
Nutch 是一個開源Java 實現的搜索引擎。它提供了我們運行自己的搜索引擎所需的全部工具。可以為什麼我們需要建立自己的搜索引擎呢?畢竟我們已經有google可以使用。這里我列出3點原因:
(1)透明度:Nutch是開放源代碼的,因此任何人都可以查看他的排序算法是如何工作的。商業的搜索引擎排序算法都是保密的,我們無法知道為什麼搜索出來的排序結果是如何算出來的。更進一步,一些搜索引擎允許競價排名,比如百度,這樣的索引結果並不是和站台內容相關的。因此 Nutch 對學術搜索和政府類站台的搜索來說,是個好選擇。因為一個公平的排序結果是非常重要的。
對搜索引擎的理解:我們並沒有google的源代碼,因此學習搜索引擎Nutch是個不錯的選擇。了解一個大型分布式的搜索引擎如何工作是一件讓人很受益的事情。在寫Nutch的過程中,從學院派和工業派借鑒了很多知識:比如:Nutch的核心部分目前已經被重新用 Map Reduce 實現了。看過開復演講的人都知道 Map Reduce 的一點知識吧。Map Reduce 是一個分布式的處理模型,最先是從 Google 實驗室提出來的。你也可以從下面獲得更多的消息。
http://www.domolo.com/bbs/list.asp?boardid=29
http://domolo.oicp.net/bbs/list.asp?boardid=29
並且 Nutch 也吸引了很多研究者,他們非常樂於嘗試新的搜索算法,因為對Nutch 來說,這是非常容易實現擴展的。
(2)擴展性:你是不是不喜歡其他的搜索引擎展現結果的方式呢?那就用 Nutch 寫你自己的搜索引擎吧。
(3)Nutch 是非常靈活的:他可以被很好的客戶訂制並集成到你的應用程序中:使用Nutch 的外掛程式機制,Nutch 可以作為一個搜索不同資訊載體的搜索平台。當然,最簡單的就是集成Nutch到你的站台,為你的使用者提供搜索服務。
Nutch 的安裝分為3個層次:基於本地文件系統,基於局域網,或者基於 internet 。不同的安裝方式具有不同的特色。比如:索引一個本地文件系統相對於其他兩個來說肯定是要穩定多了,因為沒有 網絡錯誤也不同緩存文件的拷貝。基於Internet 的搜索又是另一個極端:抓取數以千計的網頁有很多技術問題需要解決:我們從哪些頁面開始抓取?我們如何分配抓取工作?何時需要重新抓取?我們如何解決失效的連結,沒有響應的站台和重復的內容?還有如何解決對大型資料的上百個並發訪問?搭建這樣一個搜索引擎是一筆不小的投資呀!在 " Building Nutch: Open Source Search," 的作者 Mike Cafarella 和 Doug Cutting 總結如下:
: ... 一個具有完全功能的搜索系統:1億頁面索引量,每秒2個並發索引,需要每月800美元。10億頁面索引量,每秒50個頁面請求,大概需要每月30000美元。
這篇文章將為你演示如何在中等級別的網站上搭建Nutch。第一部分集中在抓取上。Nutch的抓取架構,如何運行一個抓取程序,理解這個抓取過程產生了什麼。第二部分關注搜索。演示如何運行Nutch搜索程序。以及如何訂制Nutch 。
Nutch Vs. Lucene
Nutch 是基於 Lucene的。Lucene為 Nutch 提供了文本索引和搜索的API。一個常見的問題是;我應該使用Lucene還是Nutch?最簡單的回答是:如果你不需要抓取資料的話,應該使用Lucene。常見的應用場合是:你有資料源,需要為這些資料提供一個搜索頁面。在這種情況下,最好的方式是直接從資料庫中取出資料並用Lucene API建立索引。中文使用者,可以參考 WebLucene 或者 車東 的一些列文章。如果需要中文分詞幫助還可以聯系作者。
http://domolo.oicp.net/bbs/list.asp?boardid=24
Erik Hatcher 和 Otis Gospodnetić's 的 Lucene in Action 中詳細講述了這個過程。Nutch 適用於你無法直接獲取資料庫中的網站,或者比較分散的資料源的情況下使用。
架構
總體上Nutch可以分為2個部分:抓取部分和搜索部分。抓取程序抓取頁面並把抓取回來的資料做成反向索引,搜索程序則對反向索引搜索回答使用者的請求。抓取程序和搜索程序的接口是索引。兩者都使用索引中的字段。()
實際上搜索程序和抓取程序可以分別位於不同的機器上。()
這里我們先看看Nutch的抓取部分。
抓取程序: 抓取程序是被Nutch的抓取工具驅動的。這是一組工具,用來建立和維護幾個不同的資料結構: web database, a set of segments, and the index。下面我們逐個解釋上面提到的3個不同的資料結構。
The web database, 或者WebDB, 是一個特殊存儲資料結構,用來映像被抓取網站資料的結構和屬性的集合。WebDB 用來存儲從抓取開始(包括重新抓取)的所有網站結構資料和屬性。WebDB 只是被 抓取程序使用,搜索程序並不使用它。WebDB 存儲2種實體:頁面 和 連結。頁面 表示 網絡上的一個網頁,這個網頁的Url作為標示被索引,同時建立一個對網頁內容的MD5 哈希簽名。跟網頁相關的其它內容也被存儲,包括:頁面中的連結數量(外連結),頁面抓取資訊(在頁面被重復抓取的情況下),還有表示頁面級別的分數 score 。連結 表示從一個網頁的連結到其它網頁的連結。因此 WebDB 可以說是一個網絡圖,節點是頁面,連結是邊。
Segment 是 網頁 的集合,並且它被索引。 Segment 的 Fetchlist 是抓取程序使用的 url 列表 , 它是從 WebDB中生成的。Fetcher 的輸出資料是從 fetchlist 中抓取的網頁。Fetcher 的輸出資料先被反向索引,然后索引后的結果被存儲在segment 中。 Segment 的生命周期是有限制的,當下一輪抓取開始后它就沒有用了。預設的 重新抓取間隔是30天。因此刪除超過這個時間期限的segment是可以的。而且也可以節省不少磁盤空間。Segment 的命名是 日期加時間 ,因此很直觀的可以看出他們的存活周期。
索引庫 是 反向索引所有系統中被抓取的頁面,他並不直接從頁面反向索引產生,它是合並很多小的 segment 的索引中產生的。Nutch 使用 Lucene 來建立索引,因此所有 Lucene 相關的工具 API 都用來建立索引庫。需要說明的是 Lucene 的 segment 的概念 和 Nutch 的 segment 概念是完全不同的,不要混淆哦。 可以參考 車東 的相關文章。 www.chedong.com 簡單來說 Lucene 的 segment 是 Lucene 索引庫的一部分,而 Nutch 的 Segment 是 WebDB 中 被 抓取和索引的一部分
(1)透明度:Nutch是開放源代碼的,因此任何人都可以查看他的排序算法是如何工作的。商業的搜索引擎排序算法都是保密的,我們無法知道為什麼搜索出來的排序結果是如何算出來的。更進一步,一些搜索引擎允許競價排名,比如百度,這樣的索引結果並不是和站台內容相關的。因此 Nutch 對學術搜索和政府類站台的搜索來說,是個好選擇。因為一個公平的排序結果是非常重要的。
對搜索引擎的理解:我們並沒有google的源代碼,因此學習搜索引擎Nutch是個不錯的選擇。了解一個大型分布式的搜索引擎如何工作是一件讓人很受益的事情。在寫Nutch的過程中,從學院派和工業派借鑒了很多知識:比如:Nutch的核心部分目前已經被重新用 Map Reduce 實現了。看過開復演講的人都知道 Map Reduce 的一點知識吧。Map Reduce 是一個分布式的處理模型,最先是從 Google 實驗室提出來的。你也可以從下面獲得更多的消息。
http://www.domolo.com/bbs/list.asp?boardid=29
http://domolo.oicp.net/bbs/list.asp?boardid=29
並且 Nutch 也吸引了很多研究者,他們非常樂於嘗試新的搜索算法,因為對Nutch 來說,這是非常容易實現擴展的。
(2)擴展性:你是不是不喜歡其他的搜索引擎展現結果的方式呢?那就用 Nutch 寫你自己的搜索引擎吧。
(3)Nutch 是非常靈活的:他可以被很好的客戶訂制並集成到你的應用程序中:使用Nutch 的外掛程式機制,Nutch 可以作為一個搜索不同資訊載體的搜索平台。當然,最簡單的就是集成Nutch到你的站台,為你的使用者提供搜索服務。
Nutch 的安裝分為3個層次:基於本地文件系統,基於局域網,或者基於 internet 。不同的安裝方式具有不同的特色。比如:索引一個本地文件系統相對於其他兩個來說肯定是要穩定多了,因為沒有 網絡錯誤也不同緩存文件的拷貝。基於Internet 的搜索又是另一個極端:抓取數以千計的網頁有很多技術問題需要解決:我們從哪些頁面開始抓取?我們如何分配抓取工作?何時需要重新抓取?我們如何解決失效的連結,沒有響應的站台和重復的內容?還有如何解決對大型資料的上百個並發訪問?搭建這樣一個搜索引擎是一筆不小的投資呀!在 " Building Nutch: Open Source Search," 的作者 Mike Cafarella 和 Doug Cutting 總結如下:
: ... 一個具有完全功能的搜索系統:1億頁面索引量,每秒2個並發索引,需要每月800美元。10億頁面索引量,每秒50個頁面請求,大概需要每月30000美元。
這篇文章將為你演示如何在中等級別的網站上搭建Nutch。第一部分集中在抓取上。Nutch的抓取架構,如何運行一個抓取程序,理解這個抓取過程產生了什麼。第二部分關注搜索。演示如何運行Nutch搜索程序。以及如何訂制Nutch 。
Nutch Vs. Lucene
Nutch 是基於 Lucene的。Lucene為 Nutch 提供了文本索引和搜索的API。一個常見的問題是;我應該使用Lucene還是Nutch?最簡單的回答是:如果你不需要抓取資料的話,應該使用Lucene。常見的應用場合是:你有資料源,需要為這些資料提供一個搜索頁面。在這種情況下,最好的方式是直接從資料庫中取出資料並用Lucene API建立索引。中文使用者,可以參考 WebLucene 或者 車東 的一些列文章。如果需要中文分詞幫助還可以聯系作者。
http://domolo.oicp.net/bbs/list.asp?boardid=24
Erik Hatcher 和 Otis Gospodnetić's 的 Lucene in Action 中詳細講述了這個過程。Nutch 適用於你無法直接獲取資料庫中的網站,或者比較分散的資料源的情況下使用。
架構
總體上Nutch可以分為2個部分:抓取部分和搜索部分。抓取程序抓取頁面並把抓取回來的資料做成反向索引,搜索程序則對反向索引搜索回答使用者的請求。抓取程序和搜索程序的接口是索引。兩者都使用索引中的字段。()
實際上搜索程序和抓取程序可以分別位於不同的機器上。()
這里我們先看看Nutch的抓取部分。
抓取程序: 抓取程序是被Nutch的抓取工具驅動的。這是一組工具,用來建立和維護幾個不同的資料結構: web database, a set of segments, and the index。下面我們逐個解釋上面提到的3個不同的資料結構。
The web database, 或者WebDB, 是一個特殊存儲資料結構,用來映像被抓取網站資料的結構和屬性的集合。WebDB 用來存儲從抓取開始(包括重新抓取)的所有網站結構資料和屬性。WebDB 只是被 抓取程序使用,搜索程序並不使用它。WebDB 存儲2種實體:頁面 和 連結。頁面 表示 網絡上的一個網頁,這個網頁的Url作為標示被索引,同時建立一個對網頁內容的MD5 哈希簽名。跟網頁相關的其它內容也被存儲,包括:頁面中的連結數量(外連結),頁面抓取資訊(在頁面被重復抓取的情況下),還有表示頁面級別的分數 score 。連結 表示從一個網頁的連結到其它網頁的連結。因此 WebDB 可以說是一個網絡圖,節點是頁面,連結是邊。
Segment 是 網頁 的集合,並且它被索引。 Segment 的 Fetchlist 是抓取程序使用的 url 列表 , 它是從 WebDB中生成的。Fetcher 的輸出資料是從 fetchlist 中抓取的網頁。Fetcher 的輸出資料先被反向索引,然后索引后的結果被存儲在segment 中。 Segment 的生命周期是有限制的,當下一輪抓取開始后它就沒有用了。預設的 重新抓取間隔是30天。因此刪除超過這個時間期限的segment是可以的。而且也可以節省不少磁盤空間。Segment 的命名是 日期加時間 ,因此很直觀的可以看出他們的存活周期。
索引庫 是 反向索引所有系統中被抓取的頁面,他並不直接從頁面反向索引產生,它是合並很多小的 segment 的索引中產生的。Nutch 使用 Lucene 來建立索引,因此所有 Lucene 相關的工具 API 都用來建立索引庫。需要說明的是 Lucene 的 segment 的概念 和 Nutch 的 segment 概念是完全不同的,不要混淆哦。 可以參考 車東 的相關文章。 www.chedong.com 簡單來說 Lucene 的 segment 是 Lucene 索引庫的一部分,而 Nutch 的 Segment 是 WebDB 中 被 抓取和索引的一部分
2007年10月24日
nutch 搜索中文會出現亂碼的問題
這個問題其實和 Nutch 關係不大,主要原因是使用 Tomcat 5.0 的問題。解決辦法是修改 Tomcat 的 server.xml 文件的connnector:
--
<-Connector port="8080"
maxThreads="150" minSpareThreads="25" maxSpareThreads="75"
enableLookups="false" redirectPort="8443" acceptCount="100"
connectionTimeout="20000" disableUploadTimeout="true"
URIEncoding="UTF-8" useBodyEncodingForURI="true" />
其中 URIEncoding="UTF-8" useBodyEncodingForURI="true" 是需要新增的。否則搜索欄輸入的字符預設編碼將不能正確解析。
2007年10月21日
Installing the JavaFX Script Plugin
Once you have configured the NetBeans Update Center Beta, you can now download and install the JavaFX Script plugin using the steps below.
(1) Select Tools > Update Center from the main menu of the IDE.
(2) In the Select Location of Modules page, select the NetBeans Update Center Beta check box and unselect all other checkboxes.

(3) Click Next and the wizard checks for any available updates for the plugin.
(4) In the Select Modules to Install page, select the four JavaFX Features nodes and click Add.

(5) Click Next.
(6) Click Accept in the License Agreement dialogs. The Download Modules page appears and progress is shown as the modules are downloaded.
(7) Click Next after the modules have been successfully downloaded.The View Certificate and Install Modules page is displayed list of certificates are made available for your viewing.
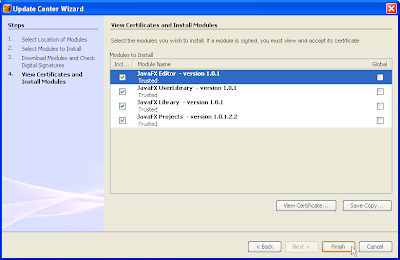
(8) Click Finish to proceed with the installation of the JavaFX plugin modules.The IDE proceeds with the installation.
(9) From the main menu, click Tools > Module Manager.The JavaFX Editor, JavaFX Projects, and JavaFX UserLibrary module nodes are now listed, as shown below. The JavaFXLibrary node can be found under the last Libraries node.
(1) Select Tools > Update Center from the main menu of the IDE.
(2) In the Select Location of Modules page, select the NetBeans Update Center Beta check box and unselect all other checkboxes.

(3) Click Next and the wizard checks for any available updates for the plugin.
(4) In the Select Modules to Install page, select the four JavaFX Features nodes and click Add.
The Include in Install pane is updated with the JavaFX modules, as shown below.

(5) Click Next.
(6) Click Accept in the License Agreement dialogs. The Download Modules page appears and progress is shown as the modules are downloaded.

(7) Click Next after the modules have been successfully downloaded.The View Certificate and Install Modules page is displayed list of certificates are made available for your viewing.

(8) Click Finish to proceed with the installation of the JavaFX plugin modules.The IDE proceeds with the installation.
(9) From the main menu, click Tools > Module Manager.The JavaFX Editor, JavaFX Projects, and JavaFX UserLibrary module nodes are now listed, as shown below. The JavaFXLibrary node can be found under the last Libraries node.

(10) Click to dismiss the Module manager.
(11) Proceed to the Getting Started with the JavaFX Script Language tutorial to create your first JavaFX Script program.
2007年10月20日
regexps
"Regular expression" is often shortened to regex or regexp (singular), or regexes, regexps, or regexen (plural).
In computing, a regular expression is a string that is used to describe or match a set of strings, according to certain syntax rules.
Regular expressions are used by many text editors, utilities, and programming languages to search and manipulate text based on patterns. For example, Perl and Tcl have a powerful regular expression engine built directly into their syntax --By Wiki
In computing, a regular expression is a string that is used to describe or match a set of strings, according to certain syntax rules.
Regular expressions are used by many text editors, utilities, and programming languages to search and manipulate text based on patterns. For example, Perl and Tcl have a powerful regular expression engine built directly into their syntax --By Wiki
Intranet(企業網路)
An intranet is a private computer network that uses Internet protocols, network connectivity to securely share part of an organization's information or operations with its employees. --by Wiki
狐狸的故事
有一隻狐狸,在路上閒逛時,眼前忽然出現一個很大的葡萄園,果實纍纍,每顆葡萄看起來都很可口,讓牠垂涎欲滴。
葡萄園的四周圍著鐵欄杆,狐狸想從欄杆的縫隙鑽進園內,卻因身體太胖了,鑽不過去。於是狐狸決定減肥,讓自己瘦下來。
牠在園外餓了三天三夜後,果然變苗條了,真是皇天不負苦心人,終於順利鑽進葡萄園內。
狐狸在園內大快朵頤,葡萄真是又甜又香啊!
不知吃了多久,牠終於心滿意足了。
但當牠想溜出園外時,卻發現自己又因為吃得太胖而鑽不出欄杆,於是只好又在園內餓了三天三夜,瘦得跟原先一樣時,才順利地鑽出園外。
回到外面世界的狐狸,看著園內的葡萄,不禁感嘆:空著肚子進去,又空著肚子出來,真是白忙一場啊!
我起初也以為這個故事告訴我們,人孑然一身來到這世界,又孑然一身的離開這個世界,到頭來還不是白忙一場!呵,這個講故事的人卻說,看問題要看重點。這個故事跟人生一樣,重點是在中間的部份:你看,狐狸在葡萄園內吃得多麼快樂啊!
「即使生命是一場空,也要空得很充實,縱然人生是白忙一場,也要忙得很快樂。」
葡萄園的四周圍著鐵欄杆,狐狸想從欄杆的縫隙鑽進園內,卻因身體太胖了,鑽不過去。於是狐狸決定減肥,讓自己瘦下來。
牠在園外餓了三天三夜後,果然變苗條了,真是皇天不負苦心人,終於順利鑽進葡萄園內。
狐狸在園內大快朵頤,葡萄真是又甜又香啊!
不知吃了多久,牠終於心滿意足了。
但當牠想溜出園外時,卻發現自己又因為吃得太胖而鑽不出欄杆,於是只好又在園內餓了三天三夜,瘦得跟原先一樣時,才順利地鑽出園外。
回到外面世界的狐狸,看著園內的葡萄,不禁感嘆:空著肚子進去,又空著肚子出來,真是白忙一場啊!
我起初也以為這個故事告訴我們,人孑然一身來到這世界,又孑然一身的離開這個世界,到頭來還不是白忙一場!呵,這個講故事的人卻說,看問題要看重點。這個故事跟人生一樣,重點是在中間的部份:你看,狐狸在葡萄園內吃得多麼快樂啊!
「即使生命是一場空,也要空得很充實,縱然人生是白忙一場,也要忙得很快樂。」
利用Axis TCP Monitor 檢視 soap package
將axis.jar複製到 Tomcat 5.5\webapps\Xfire\WEB-INF\lib 目錄下
1)先開啟TCP Monitor 從Dos下改變路徑至Tomcat 5.5\webapps\Xfire\WEB-INF\lib 之下下 Command line :java -classpath axis.jar org.apache.axis.utils.tcpmon =>出現TCP Monitor

2)請在 Listen Port# 的欄位任意輸入一個大於 1024 的整數,例如 9999,然後 click "Add" 鈕,這時候,程式會新增一個 tab,請選擇這個 tab 開始監測 SOAP 訊息。然後就出現畫面,等待連線

3)再另開一個Dos Window 執行自己寫好的Web Service ,我以HelloService.java & IHelloService.java 當例子,再另外寫了HelloServiceClient.java的Client programa)HelloService.java

b)IHelloService.java

c)HelloServiceClient.java

編譯HelloServiceClient.java 並且執行 則可以從TCP Monitor 監測到package ,則可以得到以下結果:

1)先開啟TCP Monitor 從Dos下改變路徑至Tomcat 5.5\webapps\Xfire\WEB-INF\lib 之下下 Command line :java -classpath axis.jar org.apache.axis.utils.tcpmon =>出現TCP Monitor

2)請在 Listen Port# 的欄位任意輸入一個大於 1024 的整數,例如 9999,然後 click "Add" 鈕,這時候,程式會新增一個 tab,請選擇這個 tab 開始監測 SOAP 訊息。然後就出現畫面,等待連線

3)再另開一個Dos Window 執行自己寫好的Web Service ,我以HelloService.java & IHelloService.java 當例子,再另外寫了HelloServiceClient.java的Client programa)HelloService.java

b)IHelloService.java

c)HelloServiceClient.java

編譯HelloServiceClient.java 並且執行 則可以從TCP Monitor 監測到package ,則可以得到以下結果:

Nutch Setup and Use
 Nutch作為一款剛剛誕生的開源Web搜索引擎,提供了除商業搜索引擎外的一種新的選擇。個人、企業都可通過Nutch來構建適合於自身需要的搜索引擎平台,提供適合於自身的搜索服務,而不必完全被動接收商業搜索引擎的各種約束。
Nutch作為一款剛剛誕生的開源Web搜索引擎,提供了除商業搜索引擎外的一種新的選擇。個人、企業都可通過Nutch來構建適合於自身需要的搜索引擎平台,提供適合於自身的搜索服務,而不必完全被動接收商業搜索引擎的各種約束。Nutch的工作流程可以分為兩個大的部分:抓取部分與搜索部分。抓取程序抓取頁面並把抓取回來的資料進行反向索引,搜索程序則對反向索引進行搜索回答使用者的請求,索引是聯系這兩者的紐帶。圖1是對Nutch整個工作流程的描述。
首先需要建立一個空的URL資料庫,並且把起始根urls添加到URL資料庫中(步驟1),依據URL資料庫在新創建的segment中生成fetchlist,存放了待爬行的URLs(步驟2),根據fetchlist從Internet進行相關網頁內容的爬行抓取與下載(步驟3),隨后把這些抓取到的內容解析成文本與資料(步驟4),從中提取出新的網頁連結URL,並對URL資料庫進行更新(步驟5),重復步驟2-5直到達到被指定的爬行抓取深度。以上過程構成了Nutch的整個抓取過程,可以用一個循環來對其進行描述:生成→抓取→更新→循環。
當抓取過程完成后,對抓取到的網頁進行反向索引,對重復的內容與URL進行剔除,然后對多個索引進行合並,為搜索建立統一的索引庫,而后使用者可通過由Tomcat容器提供的Nutch使用者界面提交搜索請求,然后由Lucene對索引庫進行查詢,並返回搜索結果給使用者,完成整個搜索過程。
Nutch程序採用Java語言編寫,其運行環境需要一個Tomcat容器。本文運行環境以最新的j2sdk1.4.2_12及jakarta-tomcat-5.0.28為例。
使用Nutch進行資料抓取
Nutch通過運行網絡爬蟲工具進行網絡內容的抓取,它提供了爬行企業內部網與爬行整個互聯網這兩種方式。
● 爬行企業內部網
爬行企業內部網(Intranet Crawling)這種方式適合於針對一小撮Web服務器,並且網頁數在百萬以內的情況。它使用crawl命令進行網絡爬行抓取。在進行爬行前,需要對Nutch進行一系列的配置,過程如下:
首先,需要創建一個目錄,並且在此目錄中創建包含起始根URLs的文件。我們以爬行搜狐網站(http://www.sohu.com)為例進行講述。
#cd /usr/local/nutch
#mkdir urls
#touch urls/sohu
因此文件urls/sohu的內容為:http://www.sohu.com/。依據爬行網站的實際情況,可繼續在此文件末尾添加其他URL或者在URL目錄里添加其他包含URL的文件。需要注意的是,在Nutch0.7的版中不需要創建目錄,直接創建包含起始根URL的文件即可。
接下來,要編輯conf/crawl-urlfilter.txt文件,將文中MY.DOMAIN.NAME部分替換為準備爬行的域名,並去掉前面的注釋。因此在本文中進行域名替換后的形式為:
+^http://([a-z0-9]*\.)*sohu.com/
文件conf/crawl-urlfilter.txt主要用於限定爬行的URL形式,其中URL的形式使用正則表達式進行描述。
然后,編輯文件conf/nutch-site.xml,並且必須包含以下內容:
< ?xml version="1.0"?>
< ?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
< !-- Put site-specific property overrides in this file. -->
nfiguration>
<>
<>http.agent.name< /name>
<>sohu.com< /value>
<>sohu.com< /description>
< /property>
< /configuration>
除http.agent.name外,在<> < /configuration>間一般還包括http.agent.description、http.agent.url、http.agent.email這三個選項。
最后,開始爬行抓取。完成對Nutch的配置后,運行crawal命令進行爬行。在本文中爬行腳本為:
#bin/nutch crawl urls -dir sohu -depth 5 -topN 1000
其中命令行中各參數項含義分別為:dir指定爬行結果的存放目錄,此處dir為sohu;depth指定從根URL起將要爬行的深度,此例depth設定為5;N設定每一層爬行靠前的N個URL,此例N值設定為1000。另外,crawl還有一個參數項:threads,它設定並行爬行的進程數。在爬行過程中,可通過Nutch日志文件查看爬行的進展狀態,爬行完成后結果存放在sohu目錄里。
● 爬行整個互聯網
爬行整個互聯網(Whole-web crawling)是一種大規模網絡爬行,與第一種爬行方式相對,具有更強的控制性,使用inject、generate、fetch、updatedb等比較低層次的命令,爬行量大,可能需要數台機器數周才能完成。
首先,需要下載一個包含海量URL的文件。下載完成后,將其拷貝到Nutch主目錄,並且解壓縮文件。
wget http://rdf.dmoz.org/rdf/content.rdf.u8.gz
#cd /usr/local/nutch
#cp /home/zyhua/content.rdf.u8.gz .
#gunzip content.rdf.u8.gz
content.rdf.u8包含了約三百萬個URL,在此僅隨機抽取五萬分之一的URL進行爬行。同第一種方法一樣,首先需要建立包含起始根URL的文件及其父目錄。
#mkdir urls
#bin/nutch org.apache.nutch.tools.DmozParser content.rdf.u8 -subset 50000 > urls/urllist
採用Nutch的inject命令將這些URL添加crawldb中。這里,目錄crawl是爬行資料存儲的根目錄。
#bin/nutch inject crawl/crawldb urls
然后,編輯文件conf/nutch-site.xml,內容及方法與“爬行企業內部網”類似,此處略過。接著,開始爬行抓取。可以將整個爬行抓取的命令寫成一個shell腳本,每次抓取只需執行此腳本即可,即生成→抓取→更新的過程。根據需要可反復運行此腳本進行爬行抓取。腳本範例及相應的說明如下:
#!/bin/sh
bin/nutch generate crawl/crawldb crawl/segments
lastseg=`ls -d crawl/segments/2* tail -1`
echo $lastseg
bin/nutch fetch $lastseg
bin/nutch updatedb crawl/crawldb $lastseg
#chmod u+x crawl //使其可執行。
#./crawl //運行腳本開始爬行抓取。
最后,進行索引。爬行抓取完后,需要對抓取回來的內容進行索引,以供搜索查詢。過程如下:
#bin/nutch invertlinks crawl/linkdb crawl/segments/* //倒置所有連結
#bin/nutch index crawl/indexes crawl/crawldb crawl/linkdb crawl/segments/*
使用Nutch進行資料搜索
Nutch為使用者提供了友好的搜索界面,它需要一個servlet容器來提供服務,本文選用了開源的Tomcat容器。首先,將Nutch的war文件部署到Tomcat容器里。
#rm -rf
$CATALINA_HOME/webapps/ROOT*
#cp /usr/local/nutch/nutch*.war $CATALINA_HOME/webapps/ROOT.war
啟動Tomcat,它會自動解開war文件。
#$CATALINA_HOME/bin/catalina.sh start
修改文件nutch-site.xml,指定Nutch的資料存放目錄。增加以下內容到文件nutch-site.xml中。
<>
<>searcher.dir< /name>
<>/usr/local/nutch/sohu< /value>
< /property>
< /configuration>
//在第二種爬行方法中的值為/usr/local/nutch/crawl。
修改server.xml,使輸入中文進行搜索時不出現亂碼現象。將以下內容添加到server.xml文件適當的地方。
URIEncoding=”UTF-8” useBodyEncodingForURI=”true”
配置更改完成后,重啟Tomcat服務器。
#$CATALINA_HOME/bin/catalina.sh stop
#$CATALINA_HOME/bin/catalina.sh start
Nutch的運行維護
隨著Internet上網頁的不斷更新,企業網站數量的不斷增加,需要定期進行爬行抓取,保證搜索結果的準備性與時效性。因此Nutch的運行與維護主要集中在對已有資料的增添與更新上,具體包括了爬行、索引及資料的合並等操作。主要有以下兩種典型情況。
● 重爬行抓取
重爬行抓取的作用主要表現在兩個方面,一方面是對已有內容進行更新,另一方面是發現新的內容。Nutch的Wiki網站提供的重爬行的完整腳本,其連結為:
http://wiki.apache.org/nutch/IntranetRecrawl
該連結提供了Nutch.0.7及Nutch0.8兩種版本的重爬行腳本。將腳本內容保存為文件/usr/local/nutch/bin/recrawl,便可執行,運行腳本進行重爬行。
#chmod u+x bin/recrawl
#/usr/local/nutch/bin/recrawl servlet_path crawl_dir depth adddays [topN]
//請務必使用recrawl的絕對路徑運行此腳本。
recrawl的工作過程包括以下四步:基於“生成→抓取→更新→循環”的資料爬行抓取;segments的合並及無用內容的剔除;重索引及重復內容的剔除;在Tomcat容器中重載應用程序配置。
使用Cron定期進行重爬行抓取,將如下內容添加到文件/etc/crontab末尾重啟Cron即可。
00 01 * * 6 root /usr/local/nutch/bin/recrawl
#每週六凌晨01:00進行重爬行抓取。僅供參考。
● 新增URL后的爬行抓取
主要針對第一種爬行方式,用於解決新增URL時的爬行問題。主要包括以下幾步:對新增URL的爬行抓取;新資料與已有資料的合並;重載應用程序配置。對新增URL的爬行方式與舊URLs的爬行方式相同。Nutch的Wiki網站同樣提供了進行資料合並的腳本代碼,連結為:
http://wiki.apache.org/nutch/MergeCrawl
將其保存為文件/usr/local/nutch/bin/mergecrawl,使可執行,進行資料合並。
#chmod u+x bin/mergecrawl
#bin/mergecrawl merge_dir dir1 dir2 ...
修改$CATALINA_HOME/webapps/ROOT/WEB-INF/classes/nutch-site.xml文件中searcher.dir屬性的值為新目錄名。在Tomcat服務器中重載應用程序配置。
#touch $CATALINA_HOME/webapps/ROOT/WEB-INF/web.xml
Tomcat Server's error logs
error message: WebappClassLoader: validateJarFile(D:\netbank\jsp\WEB-INF\lib\servlet.jar) - jar not loaded. See Servlet Spec 2.3, section 9.7.2. Offending class: javax/servlet/Servlet.class
Solution: 比對一下Tomcat中common\lib\*.jar和應用的.jar日期就知道了,Tomcat中有的,就不要重覆佈署了,删除即可。
Solution: 比對一下Tomcat中common\lib\*.jar和應用的.jar日期就知道了,Tomcat中有的,就不要重覆佈署了,删除即可。
訂閱:
文章 (Atom)

{kind=link}