某字串 String str="abc"def" ;
切成 abc & def
StringTokenizer token=new StringTokenizer(str,"\ " ");
PS. 轉義字符 "\ " "
2007年12月22日
2007年12月21日
Set Java VM Memory Size in NetBeans
在NetBeans下某Project右鍵點開 :
Properties >> Categories >> Run >> VM Options >> 設定!(-Xmx512m)
Properties >> Categories >> Run >> VM Options >> 設定!(-Xmx512m)
2007年12月19日
Java Garbage Collection
自動記憶體管理也就是俗稱的垃圾收集(garbage-collection),可以讓程式員減輕許多負擔,也減少程式員犯錯的機會,所以相當受歡迎。從早期的 Smalltalk,Eiffel,到近期的 Java,C#,Python,REBOL,Ruby... 等,通通支援垃圾收集。垃圾收集差不多已經成了新一代高階程式語言必備的功能。
在 Java 中,你不需要主動刪除物件,而是由 Java 虛擬機器代勞。Java 虛擬機器會「持續追蹤」每個物件被使用的情形,如果某物件未被用到,Java 虛擬機器就會自動將其釋放。而要如何「持續追蹤」,實作細節留給 Java 虛擬機器的實作者發揮。
在早期,許多虛擬機器只是將垃圾收集實作成一個執行緒,一再進行檢查,遇到垃圾就釋放其記憶體。因為垃圾收集應該盡量不要影響到原程式的執行,所以虛擬機器將此執行緒的優先權設為 0(最低)。如此一來,當系統有其它執行緒在運作時,就不會進行垃圾收集,所以常常很久才會收集到垃圾,造成記憶體不足。但又不能因此調高其優先權,否則對 Java 的執行效率是一大打擊。所以,我們這些 Java 程式員的電腦 RAM 都要至少 256 MB,否則根本沒辦法順利執行 JBuilder 或 VisualAge for Java 等 Java 開發工具,因為這些開發工具本身就是專門吃記憶體的 Java 程式。我甚至在我的筆記型電腦上裝了 512MB 的 RAM。
於是許多人懷念起 C/C++ 來了,他們認為如果 Java 能同時支援自動記憶體管理和手動記憶體管理,那麼該有多好!他們甚至希望 Java 未來的版本能允許他們主動釋放記憶體,比方說:
如果你也這麼希望的話,我勸你早點死了這條心吧!Java 語言的主要精神之一是 robust,如果 Java 同時支援這兩種記憶體管理的話,可能會造成程式中有許多潛在的 Bug,記憶體不當存取的問題會比 C/C++ 更嚴重,所以是不可能這麼做的。
java.lang.System.gc() 或 java.lang.Runtime.gc() 的 gc 指的就是 garbage-collection,不過根據文件的說明,它的作用只是「建議」Java 虛擬機器快去收垃圾,而不「保證」會去收垃圾。文件都寫得如此謙虛了,你也不應該對它寄予太多厚望。對於記憶體資源消耗太多的缺失,目前你能做的是:
1. 改用一個記憶體管理方式好一點的虛擬機器:垃圾收集是一個豐富又龐大的主題。垃圾收集的
演算法有數百種可能,而且各有專長。許多虛擬機器採用的演算法都不太一樣,建議各位多去
比較幾家。
2. 少製造垃圾:許多時候你製造了一堆不該製造的垃圾,比方說:該用固定式陣列的時候卻用
Vector,該用 StringBuffer 的時候卻用 String...... 等等。這麼會製造垃圾,再多記憶體也不夠
用。
3. 不再使用的物件要盡早設定為 null,以便早點被當成垃圾清掉。
4. 花錢多買一些 RAM(砸錢解決問題)。
在 Java 中,你不需要主動刪除物件,而是由 Java 虛擬機器代勞。Java 虛擬機器會「持續追蹤」每個物件被使用的情形,如果某物件未被用到,Java 虛擬機器就會自動將其釋放。而要如何「持續追蹤」,實作細節留給 Java 虛擬機器的實作者發揮。
在早期,許多虛擬機器只是將垃圾收集實作成一個執行緒,一再進行檢查,遇到垃圾就釋放其記憶體。因為垃圾收集應該盡量不要影響到原程式的執行,所以虛擬機器將此執行緒的優先權設為 0(最低)。如此一來,當系統有其它執行緒在運作時,就不會進行垃圾收集,所以常常很久才會收集到垃圾,造成記憶體不足。但又不能因此調高其優先權,否則對 Java 的執行效率是一大打擊。所以,我們這些 Java 程式員的電腦 RAM 都要至少 256 MB,否則根本沒辦法順利執行 JBuilder 或 VisualAge for Java 等 Java 開發工具,因為這些開發工具本身就是專門吃記憶體的 Java 程式。我甚至在我的筆記型電腦上裝了 512MB 的 RAM。
於是許多人懷念起 C/C++ 來了,他們認為如果 Java 能同時支援自動記憶體管理和手動記憶體管理,那麼該有多好!他們甚至希望 Java 未來的版本能允許他們主動釋放記憶體,比方說:
|
如果你也這麼希望的話,我勸你早點死了這條心吧!Java 語言的主要精神之一是 robust,如果 Java 同時支援這兩種記憶體管理的話,可能會造成程式中有許多潛在的 Bug,記憶體不當存取的問題會比 C/C++ 更嚴重,所以是不可能這麼做的。
java.lang.System.gc() 或 java.lang.Runtime.gc() 的 gc 指的就是 garbage-collection,不過根據文件的說明,它的作用只是「建議」Java 虛擬機器快去收垃圾,而不「保證」會去收垃圾。文件都寫得如此謙虛了,你也不應該對它寄予太多厚望。對於記憶體資源消耗太多的缺失,目前你能做的是:
1. 改用一個記憶體管理方式好一點的虛擬機器:垃圾收集是一個豐富又龐大的主題。垃圾收集的
演算法有數百種可能,而且各有專長。許多虛擬機器採用的演算法都不太一樣,建議各位多去
比較幾家。
2. 少製造垃圾:許多時候你製造了一堆不該製造的垃圾,比方說:該用固定式陣列的時候卻用
Vector,該用 StringBuffer 的時候卻用 String...... 等等。這麼會製造垃圾,再多記憶體也不夠
用。
3. 不再使用的物件要盡早設定為 null,以便早點被當成垃圾清掉。
4. 花錢多買一些 RAM(砸錢解決問題)。
DOM文件作業和XML文件互相轉換的java實作
簡介︰該文簡要描述了 DOM 的概念和內部邏輯結構,提供了 DOM 文件作業和 XML 文件互相轉換的 java 實作過程。
1. DOM簡介
目前,W3C 已於2000年11月13日推出了規範 DOM level 2。文件物件模型(DOM)是 HTML 和 XML 文件的程式化介面規範,它與平台和語言是無關的,因而可以用各種語言在各種平臺上實作。該模型定義了 THML 和 XML 文件在記憶體中的邏輯結構(即為文件),提供了存取、存取 THML 和 XML 文件的方法。利用 DOM 規範,可以實作 DOM 文件和 XML 之間的相互轉換,巡訪、作業相應 DOM 文件的內容。可以說,要自由的操縱 XML 文件,就要用到 DOM 規範。
2. DOM 內部邏輯結構
DOM 文件中的邏輯結構可以用節點樹的形式進行描述。透過對 XML 文件的解析處理,XML 文件中的元素便轉換為 DOM 文件中的節點物件。DOM 的文件節點有 Document、Element、Comment、Type 等等節點類型,其中每一個 DOM 文件必須有一個 Document 節點,並且為節點樹的根節點。它可以有子節點,或者葉子節點如 Text 節點、Comment 節點等。任何的格式良好的 XML 文件中的每一個元素均有 DOM 文件中的一個節點類型與之對應。利用 DOM 介面將 XML 文件轉換成 DOM 文件後,我們就可以自由的處理 XML 文件了。
3. java 中的 DOM 介面
DOM 規範提供的 API 的規範,目前 Sun 公司推出的 jdk1.4 測試版中的 java API 遵循了 DOM level 2 Core 推薦介面的語義說明,提供了相應的 java 語言的實作。
在 org.xml.dom 中,jkd1.4 提供了 Document、DocumentType、Node、NodeList、Element、Text 等介面,這些介面均是存取 DOM 文件所必須的。我們可以利用這些介面建立、巡訪、修改 DOM 文件。
在 javax.xml.parsers 中,jkd1.4 提供的 DoumentBuilder和DocumentBuilderFactory 組合可以對 XML 文件進行解析,轉換成 DOM 文件。
在 javax.xml.transform.dom 和 javax.xml.transform.stream 中,jdk1.4 提供了 DOMSource 類別和 StreamSource 類別,可以用來將更新後的 DOM 文件寫入產生的 XML 文件中。
4. 範例程式
4.1 將 XML 文件轉換成 DOM 文件
這個過程是獲得一個 XML 文件解析器,解析 XML 文件轉換成 DOM 文件的過程。
Jdk1.4中,Document介面描述了對應於整個XML文件的文件樹,提供了對文件資料的存取,是該步驟的目標。Document 介面可以從類別 DocumentBuilder 中取得,該類別含有了從 XML 文件獲得 DOM 文件實體的 API。XML 的解析器可以從類別 DocumentBuilderFactory 中取得。在 jdk1.4 中,XML 文件轉換成 DOM 文件可以有如下程式碼實作︰
4.3 修改DOM文件
修改 DOM 文件的 API 在 DOM level 2 Core規範中做了說明,jkd1.4 中的 org.xml.dom 中實作了這些 API。修改 DOM 文件作業主要集中在 Document、Element、Node、Text 等類別中,這裡給出的例子中是在解析出的 DOM 文件中增加一系列物件,對應與在 XML 文件中增加一條記錄。

gold coast optometrists Counter
1. DOM簡介
目前,W3C 已於2000年11月13日推出了規範 DOM level 2。文件物件模型(DOM)是 HTML 和 XML 文件的程式化介面規範,它與平台和語言是無關的,因而可以用各種語言在各種平臺上實作。該模型定義了 THML 和 XML 文件在記憶體中的邏輯結構(即為文件),提供了存取、存取 THML 和 XML 文件的方法。利用 DOM 規範,可以實作 DOM 文件和 XML 之間的相互轉換,巡訪、作業相應 DOM 文件的內容。可以說,要自由的操縱 XML 文件,就要用到 DOM 規範。
2. DOM 內部邏輯結構
DOM 文件中的邏輯結構可以用節點樹的形式進行描述。透過對 XML 文件的解析處理,XML 文件中的元素便轉換為 DOM 文件中的節點物件。DOM 的文件節點有 Document、Element、Comment、Type 等等節點類型,其中每一個 DOM 文件必須有一個 Document 節點,並且為節點樹的根節點。它可以有子節點,或者葉子節點如 Text 節點、Comment 節點等。任何的格式良好的 XML 文件中的每一個元素均有 DOM 文件中的一個節點類型與之對應。利用 DOM 介面將 XML 文件轉換成 DOM 文件後,我們就可以自由的處理 XML 文件了。
3. java 中的 DOM 介面
DOM 規範提供的 API 的規範,目前 Sun 公司推出的 jdk1.4 測試版中的 java API 遵循了 DOM level 2 Core 推薦介面的語義說明,提供了相應的 java 語言的實作。
在 org.xml.dom 中,jkd1.4 提供了 Document、DocumentType、Node、NodeList、Element、Text 等介面,這些介面均是存取 DOM 文件所必須的。我們可以利用這些介面建立、巡訪、修改 DOM 文件。
在 javax.xml.parsers 中,jkd1.4 提供的 DoumentBuilder和DocumentBuilderFactory 組合可以對 XML 文件進行解析,轉換成 DOM 文件。
在 javax.xml.transform.dom 和 javax.xml.transform.stream 中,jdk1.4 提供了 DOMSource 類別和 StreamSource 類別,可以用來將更新後的 DOM 文件寫入產生的 XML 文件中。
4. 範例程式
4.1 將 XML 文件轉換成 DOM 文件
這個過程是獲得一個 XML 文件解析器,解析 XML 文件轉換成 DOM 文件的過程。
Jdk1.4中,Document介面描述了對應於整個XML文件的文件樹,提供了對文件資料的存取,是該步驟的目標。Document 介面可以從類別 DocumentBuilder 中取得,該類別含有了從 XML 文件獲得 DOM 文件實體的 API。XML 的解析器可以從類別 DocumentBuilderFactory 中取得。在 jdk1.4 中,XML 文件轉換成 DOM 文件可以有如下程式碼實作︰
//獲得一個 XML 文件的解析器
DocumentBuilderFactory factory =
DocumentBuilderFactory.newInstance();
//解析 XML 文件產生 DOM 文件的介面類別,以便存取 DOM。
DocumentBuilder builder =
factory.newDocumentBuilder();
document =
builder.parse( new File(FileName) );
4.2 巡訪 DOM 文件
獲得介面類別 document 實體後,可以對 DOM 的文件樹進行存取。要巡訪 DOM 文件,首先要獲得 Root 元素。然後獲得 Root 元素的子節點清單。這裡透過遞迴的方法實作巡訪的目的。
//獲得 Root 元素
Element element = document.getDocumentElement();
//獲得 Root 元素的子節點清單
nodelist = element.getChildNodes();
//用遞迴方法實作 DOM 文件的巡訪
GetElement(nodelist);
其中 GetElement 方法實作如下︰
public void GetElement(NodeList nodelist){
Node cnode;
int i,len;
String str;
if(nodelist.getLength() == 0){
// 該節點沒有子節點
return;
}
for(i=0;i 1)
System.out.println(" "+str+" "+len);
}
}
}
4.3 修改DOM文件
修改 DOM 文件的 API 在 DOM level 2 Core規範中做了說明,jkd1.4 中的 org.xml.dom 中實作了這些 API。修改 DOM 文件作業主要集中在 Document、Element、Node、Text 等類別中,這裡給出的例子中是在解析出的 DOM 文件中增加一系列物件,對應與在 XML 文件中增加一條記錄。
// 獲得 Root 物件
Element root = document.getDocumentElement();
// 在 DOM 文件中增加一個 Element 節點
Element booktype =
document.createElement("COMPUTES");
//將該節點轉換成 root 物件的子節點
root.appendChild(cdrom);
//在 DOM 文件中增加一個 Element 節點
Element booktitle =
document.createElement("Title");
//將該節點轉換成 booktype 物件的子節點
booktype.appendChild(booktitle);
//在 DOM 文件中增加一個 Text 節點
Text bookname =
document.createTextNode("understand Corba");
//將該節點轉換成 bookname 物件的子節點
booktitle.appendChild(bookname);
// 獲得將 DOM 文件轉換為 XML 文件的轉換器,
在 jdk1.4 中,有類別 TransformerFactory
// 來實作,類別 Transformer 實作轉換 vPI。
TransformerFactory tfactory =
TransformerFactory.newInstance();
Transformer transformer =
tfactory.newTransformer();
// 將 DOM 物件轉換為 DOMSource 類別物件,該物件表現
為轉換成別的表達形式的訊息容器。
DOMSource source =
new DOMSource(document);
// 獲得一個 StreamResult 類別物件,該物件是 DOM 文件
轉換成的其它形式的文件的容器,可以是 XML 文件,
純文字文件,HTML 文件。這裡為一個 XML 文件。
StreamResult result =
new StreamResult(new File(“text.xml”));
// 呼叫 API,將 DOM 文件轉換成 XML 文件。
transformer.transform(source,result);
gold coast optometrists Counter
2007年12月18日
StringBuffer
1. 處理大資料量時, 用StringBuffer能解決Out of Heap memory的問題
2. 清空StringBuffer :
2. 清空StringBuffer :
1 | StringBuffer str=new StringBuffer(); |
2007年12月17日
Bat File
一些Windows批次檔(Batch File)專用指令:
1.rem:批次檔的註解,可增加批次檔的閱讀性,類似Java的單行註解//。
2.echo:將文字輸出於螢幕上,類似Java的System.out.print()。
3.echo on:將批次檔內所下的指令全部顯示在螢幕上。
4.echo off:批次檔內所下的指令全部隱藏,不顯示於螢幕上。
5.goto:轉移控制權,可以指示批次檔跳至某一標記。
6.@:前面加上@符號的指令,執行批次檔時不會將指令文字敘述顯示於螢幕上。
7.%:批次檔參數,最多可以有10個參數值(由%1至%10),於批次檔內類似Java
的main(String[] args)參數用法,%1等於args[0]。
8.pause:暫停批次檔的執行,並在螢幕上顯示Press any key to continue。
9.if exist:檢查某一檔案是否存在,若存在則條件成立,執行指定的命令。例n
如果Test.java不存在的話,執行test.bat會顯示出Test.java檔案不存在。
如果Test.java存在的話,執行test.bat時便會呼叫javacBatTest.bat,然後
編譯與執行Test.java並將結果顯示於螢幕上。
10.if 字串1==字串2:2字串相等的話,則執行所指定的指令。
11.if not:當測試條件不成立時才執行後面命令。例:
如果執行此BAT的作業系統是NT、2000、XP pro則會顯示"此作業系統為NT
架構",如果為98、Me、XP home則會顯示"此作業系統非NT架構"。
12.if errorlevel:由OS所管理的一個系統變數,目的是監視所有錯誤發
生的情況。
13.call:模組化設計,可用來呼叫另一個批次檔,類似java中method的呼叫。
1.rem:批次檔的註解,可增加批次檔的閱讀性,類似Java的單行註解//。
2.echo:將文字輸出於螢幕上,類似Java的System.out.print()。
3.echo on:將批次檔內所下的指令全部顯示在螢幕上。
4.echo off:批次檔內所下的指令全部隱藏,不顯示於螢幕上。
5.goto:轉移控制權,可以指示批次檔跳至某一標記。
6.@:前面加上@符號的指令,執行批次檔時不會將指令文字敘述顯示於螢幕上。
7.%:批次檔參數,最多可以有10個參數值(由%1至%10),於批次檔內類似Java
的main(String[] args)參數用法,%1等於args[0]。
8.pause:暫停批次檔的執行,並在螢幕上顯示Press any key to continue。
9.if exist:檢查某一檔案是否存在,若存在則條件成立,執行指定的命令。例n
1 | @echo off |
1 | @echo off |
如果Test.java不存在的話,執行test.bat會顯示出Test.java檔案不存在。
如果Test.java存在的話,執行test.bat時便會呼叫javacBatTest.bat,然後
編譯與執行Test.java並將結果顯示於螢幕上。
10.if 字串1==字串2:2字串相等的話,則執行所指定的指令。
11.if not:當測試條件不成立時才執行後面命令。例:
1 | @echo off |
如果執行此BAT的作業系統是NT、2000、XP pro則會顯示"此作業系統為NT
架構",如果為98、Me、XP home則會顯示"此作業系統非NT架構"。
12.if errorlevel:由OS所管理的一個系統變數,目的是監視所有錯誤發
生的情況。
13.call:模組化設計,可用來呼叫另一個批次檔,類似java中method的呼叫。
2007年12月12日
判斷中文字
boolean isTraditionalChineseCharacter(char c) {
Character.UnicodeBlock block =
Character.UnicodeBlock.of(c);
if(!
Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS.equals(block) &&!
Character.UnicodeBlock.CJK_COMPATIBILITY_IDEOGRAPHS.equals(block) &&!
Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS_EXTENSION_A.equals(block))
{
return false;
}
try {
String s = ""+c;
return s.equals(new String(s.getBytes("MS950"), "MS950"));
} catch (java.io.UnsupportedEncodingException e) {
return false; }
}
Character.UnicodeBlock block =
Character.UnicodeBlock.of(c);
if(!
Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS.equals(block) &&!
Character.UnicodeBlock.CJK_COMPATIBILITY_IDEOGRAPHS.equals(block) &&!
Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS_EXTENSION_A.equals(block))
{
return false;
}
try {
String s = ""+c;
return s.equals(new String(s.getBytes("MS950"), "MS950"));
} catch (java.io.UnsupportedEncodingException e) {
return false; }
}
2007年12月6日
ANSI、BIG5 與 UTF-8
使用哪種編碼好?
UTF-8 可以處理多國語言,Big5 不行,所以我自己的習慣是 ColdFusion 連MySQL 設定 UTF-8 編碼 ( 所以 MySQL 內儲存的通通是 UTF-8 資料 )、<cfprocessingdirective> 那三行程式我也設 UTF-8、若有 meta 標籤宣告編碼,我也宣告為 UTF-8、Dreamweaver 預設編碼我也設 UTF-8,反正能設 UTF-8 的我通通都用 UTF-8,就不會在任何一個環節發生亂碼的問題了。
ANSI 檔跟 UTF8 檔的差別
UTF-8 編碼的範圍包括了 ANSI,在 UTF-8 中有維持原來的 ANSI 字元編碼,所以我們才會在發現亂碼的時候都是中文或日文等變成亂碼,英文字都正常顯示。
UTF-8 可以處理多國語言,Big5 不行,所以我自己的習慣是 ColdFusion 連MySQL 設定 UTF-8 編碼 ( 所以 MySQL 內儲存的通通是 UTF-8 資料 )、<cfprocessingdirective> 那三行程式我也設 UTF-8、若有 meta 標籤宣告編碼,我也宣告為 UTF-8、Dreamweaver 預設編碼我也設 UTF-8,反正能設 UTF-8 的我通通都用 UTF-8,就不會在任何一個環節發生亂碼的問題了。
ANSI 檔跟 UTF8 檔的差別
UTF-8 編碼的範圍包括了 ANSI,在 UTF-8 中有維持原來的 ANSI 字元編碼,所以我們才會在發現亂碼的時候都是中文或日文等變成亂碼,英文字都正常顯示。
2007年11月29日
增加Netbeans預設的memory大小
很多使用 NetBeans 的朋友,常會抱怨,NetBeans 用起來慢慢的!
這很大部份是因為 JVM 在處理一些 Housekeeping 動作所造成的 (如:Garbage collection、Memory allocate 等等)!
所以我們就來誏這些動作不要太頻繁的運作,而要作到如此,我們要來改一個小地方!
在你安裝完 NetBeans 後,會在你安裝 NetBeans 的目錄下看到一個 etc 的目錄!不用害怕進去就對了!
而在其中有一檔案 netbeans.conf,而這就是今天的主角了!用你的 Text Editor 打開它!
此檔案有一些說明的註解外,就是 Key\Value Pair 了!來,現在找到
netbeans_default_options
這個 Key !
其 Value 在 NetBeans 4.1 的預設下為
"-J-Xms32m -J-Xmx128m -J-XX:PermSize=32m -J-XX:MaxPermSize=96m -J-Xverify:none"
這樣的參數看來還不陌生吧!
-J-Xms 這是在設定此次 JVM 最小(預設)的記憶體,
-J-Xmx 則是設定此次 JVM 最大可使用的記憶體!
如果最小(預設)的記憶体不夠用時,JVM 就會花時間來多增加記憶體來使用
(但不會超過 -J-Xmx 所設定的大小)
如果最大可使用的記憶体不夠用時,JVM 就會花時間來清理記憶體,
以維持在 -J-Xmx 所設定的大小內!
而我們所要做的大多就只要加大 -J-Xms 的部份,歸類一下有兩種作法!
1、-J-Xms 小於 -J-Xmx,但調整後的 -J-Xmx 大於預設的值!
這樣的設定是加大 -J-Xms 的值,讓 JVM 少花時間在增加記憶體上!
但當其不管用時,還是會做增加記憶體的動作,增加上限到 -J-Xmx 設定的值!
2、-J-Xms 等於 -J-Xmx!
這樣的設定就不會有 JVM 花時間在增加記憶體上的問題了!
因為一次就割了一大塊記憶體!
希望以上的分享可以幫的上有需求的朋友!
這很大部份是因為 JVM 在處理一些 Housekeeping 動作所造成的 (如:Garbage collection、Memory allocate 等等)!
所以我們就來誏這些動作不要太頻繁的運作,而要作到如此,我們要來改一個小地方!
在你安裝完 NetBeans 後,會在你安裝 NetBeans 的目錄下看到一個 etc 的目錄!不用害怕進去就對了!
而在其中有一檔案 netbeans.conf,而這就是今天的主角了!用你的 Text Editor 打開它!
此檔案有一些說明的註解外,就是 Key\Value Pair 了!來,現在找到
netbeans_default_options
這個 Key !
其 Value 在 NetBeans 4.1 的預設下為
"-J-Xms32m -J-Xmx128m -J-XX:PermSize=32m -J-XX:MaxPermSize=96m -J-Xverify:none"
這樣的參數看來還不陌生吧!
-J-Xms 這是在設定此次 JVM 最小(預設)的記憶體,
-J-Xmx 則是設定此次 JVM 最大可使用的記憶體!
如果最小(預設)的記憶体不夠用時,JVM 就會花時間來多增加記憶體來使用
(但不會超過 -J-Xmx 所設定的大小)
如果最大可使用的記憶体不夠用時,JVM 就會花時間來清理記憶體,
以維持在 -J-Xmx 所設定的大小內!
而我們所要做的大多就只要加大 -J-Xms 的部份,歸類一下有兩種作法!
1、-J-Xms 小於 -J-Xmx,但調整後的 -J-Xmx 大於預設的值!
這樣的設定是加大 -J-Xms 的值,讓 JVM 少花時間在增加記憶體上!
但當其不管用時,還是會做增加記憶體的動作,增加上限到 -J-Xmx 設定的值!
2、-J-Xms 等於 -J-Xmx!
這樣的設定就不會有 JVM 花時間在增加記憶體上的問題了!
因為一次就割了一大塊記憶體!
希望以上的分享可以幫的上有需求的朋友!
2007年11月20日
116個副檔名解釋 及開啟方式
001 分片壓縮檔 WinRAR3.0
3ds 格式檔 3ds max
ace 壓縮檔 WinRAR 3.0
ade 文件檔 PowerPoint
arj 壓縮檔 WinRAR 3.0
asf 影片檔 Media player
asp 程式原始碼 Internet Explorer, 用記事本開啟編輯
avi 影片檔 Media player
bak 備份檔 如果不需要可直接刪除
bat 批次檔 滑鼠點兩下執行或用記事本編輯
bik 影片檔 Bink Player
bin 燒錄映像檔 CDMate
bkf 備份檔 Windows XP內建的"備份或還原精靈"
bmp 圖片檔 小畫家, ACDsee
bwi 燒錄映像檔 BlindSuite
c2d 燒錄映像檔 WinOnCD
cab 壓縮檔 Cabinet Manager 99
ccd 燒錄映像檔 配合img及sub檔用CloneCD開啟
cdi 燒錄映像檔 Padus DiscJuggler
cdp 燒錄映像檔 NTI CDMaker
cdr 文件檔 CorelDraw
cfg 設定檔 通常可用記事本開啟
cfm 網頁程式檔 Internet Explorer, 用記事本開啟編輯
cgi 網頁程式檔 Internet Explorer, 用記事本開啟編輯
cif 燒錄映像檔 Easy CD Creator
com 命令檔 滑鼠點兩下執行
csv 通訊錄 用Outlook Express或其他郵件軟體匯入
cur 滑鼠游標檔 ACDSee
dao 燒錄映像檔 Duplicator
dat 影片檔 Media player
dbx 郵件檔 用Outlook Express匯入
divx 影片檔 需裝Divx5.02, 用Media player開啟
dll 動態聯絡檔 系統重要檔案, 不要隨意刪除
doc 文件檔 Word
dot 範本檔 Word
drv 驅動程式檔 安裝硬體時需要此檔
dwg 圖檔 AutoCAD
eml 郵件檔 Outlook Express
eps 圖片檔 ACDSee
exe 執行檔 滑鼠點兩下執行
fcd 虛擬光碟檔 Virtual CD-ROM
gcd 燒錄映像檔 Prassi CD Right Plus
gho 備份檔 Ghost還原程式
gif 圖片檔 ACDSee
hlp 說明檔 滑鼠點兩下執行
htm 網頁檔 Internet Explorer
html 網頁檔 Internet Explorer
ico 圖示檔 ACDSee
igs 文件檔 Lotus Notes
ime 輸入法主檔 若刪除此檔會導致無法使用輸入法
inf 組態設定檔 可用記事本開啟, 但不要隨意修改
ini 組態設定檔 可用記事本開啟, 但不要隨意修改
iso 燒錄映像檔 Nero或大部分的燒錄軟體
jar 壓縮檔 WinRAR 3.0
jpg 圖片檔 ACDSee, Photoshop等秀圖, 影像處理軟體
js java script檔 可用記事本開啟
lnk Windows捷徑檔 滑鼠點兩下執行
log 記錄檔 通常可用記事本開啟
lzh 壓縮檔 WinRAR 3.0
m3u Winamp play播放清單 Winamp
mht 網頁封存檔 Internet Explorer
mid 音樂檔 Media player
mov 影片檔 Quicktime
mp3 聲音檔 Media player
mpg 影片檔 Media player
msi 安裝檔 滑鼠點兩下執行
mv2 影片檔 PowerDVD
nrg 燒錄映像檔 Nero
ogg 聲音檔 Winamp
pcx 圖片檔 ACDsee, Photoshop等秀圖, 影像處理軟體
pdb 資料庫 Palm作業系統專用
pdf 文件檔 Acrobat Reader
php 網頁程式檔 Internet Explorer, 用記事本開啟編輯
pls mp3播放列表 Winamp
png 圖片檔 ACDsee, Photoshop等秀圖, 影像處理軟體
pot PowerPoint範本檔 PowerPoint
pps PowerPoint播放檔 僅限播放, 無法修改
ppt PowerPoint文件檔 PowerPoint
prc 可執行程式檔 Palm作業系統專用
psd 圖片檔 Photoshop專用的格式
pwl Windows密碼檔 存放Windows中各式密碼
ra 影片檔 Realplayer
ram 影片檔 Realplayer
rar 壓縮檔 WinRAR3.0
reg 登錄檔 滑鼠點兩下匯入或用記事本開啟編輯
rm 影片檔 Realplayer
rtf 文字檔 Word
sav 儲存檔 遊戲進度的記錄檔案
scr 螢幕保護程式檔 按滑鼠右鍵選擇安裝
sfv 檢查檔 FireSFV
swf 動畫檔 Flash
swp 系統置換檔 管理虛擬記憶體檔案, 勿隨意刪除
sys 系統檔 程式重要檔案, 勿隨意刪除
tab 輸入法的對照表 記事本
tar 壓縮檔 WinRAR3.0
tbl 輸入法字碼檔 輸入法所需使用的檔案
tga 圖片檔 ACDSee, Photoshop等秀圖, 影像處理軟體
tgz 壓縮檔 WinRAR 3.0
tif 圖片檔 ACDSee, Photoshop等秀圖, 影像處理軟體
tmp 暫存檔 程式視需要建立, 可刪除
ttf 字形檔 在控制台中的字型資料夾中新增
txt 文字檔 記事本, Word等可編輯文字的程式
uin ICQ使用者資訊檔 記錄ICQ號碼
url 網頁位址 Internet Explorer
vbs VB script檔 可用記事本開啟
vob 影片檔 PowerDVD
voc 聲音檔 Media player
wab 通訊錄檔 Outlook Express使用
wav 聲音檔 Media player
wbk Word備份檔 Word
wmf 聲音檔 Media player
wri 文件檔 小作家
wsz Winamp的外觀檔 用Winamp匯入
xls excel文件檔 Excel
xml 跨平台網頁檔 Internet Explorer
zip 壓縮檔 Winzip, WinRAR3.0
3ds 格式檔 3ds max
ace 壓縮檔 WinRAR 3.0
ade 文件檔 PowerPoint
arj 壓縮檔 WinRAR 3.0
asf 影片檔 Media player
asp 程式原始碼 Internet Explorer, 用記事本開啟編輯
avi 影片檔 Media player
bak 備份檔 如果不需要可直接刪除
bat 批次檔 滑鼠點兩下執行或用記事本編輯
bik 影片檔 Bink Player
bin 燒錄映像檔 CDMate
bkf 備份檔 Windows XP內建的"備份或還原精靈"
bmp 圖片檔 小畫家, ACDsee
bwi 燒錄映像檔 BlindSuite
c2d 燒錄映像檔 WinOnCD
cab 壓縮檔 Cabinet Manager 99
ccd 燒錄映像檔 配合img及sub檔用CloneCD開啟
cdi 燒錄映像檔 Padus DiscJuggler
cdp 燒錄映像檔 NTI CDMaker
cdr 文件檔 CorelDraw
cfg 設定檔 通常可用記事本開啟
cfm 網頁程式檔 Internet Explorer, 用記事本開啟編輯
cgi 網頁程式檔 Internet Explorer, 用記事本開啟編輯
cif 燒錄映像檔 Easy CD Creator
com 命令檔 滑鼠點兩下執行
csv 通訊錄 用Outlook Express或其他郵件軟體匯入
cur 滑鼠游標檔 ACDSee
dao 燒錄映像檔 Duplicator
dat 影片檔 Media player
dbx 郵件檔 用Outlook Express匯入
divx 影片檔 需裝Divx5.02, 用Media player開啟
dll 動態聯絡檔 系統重要檔案, 不要隨意刪除
doc 文件檔 Word
dot 範本檔 Word
drv 驅動程式檔 安裝硬體時需要此檔
dwg 圖檔 AutoCAD
eml 郵件檔 Outlook Express
eps 圖片檔 ACDSee
exe 執行檔 滑鼠點兩下執行
fcd 虛擬光碟檔 Virtual CD-ROM
gcd 燒錄映像檔 Prassi CD Right Plus
gho 備份檔 Ghost還原程式
gif 圖片檔 ACDSee
hlp 說明檔 滑鼠點兩下執行
htm 網頁檔 Internet Explorer
html 網頁檔 Internet Explorer
ico 圖示檔 ACDSee
igs 文件檔 Lotus Notes
ime 輸入法主檔 若刪除此檔會導致無法使用輸入法
inf 組態設定檔 可用記事本開啟, 但不要隨意修改
ini 組態設定檔 可用記事本開啟, 但不要隨意修改
iso 燒錄映像檔 Nero或大部分的燒錄軟體
jar 壓縮檔 WinRAR 3.0
jpg 圖片檔 ACDSee, Photoshop等秀圖, 影像處理軟體
js java script檔 可用記事本開啟
lnk Windows捷徑檔 滑鼠點兩下執行
log 記錄檔 通常可用記事本開啟
lzh 壓縮檔 WinRAR 3.0
m3u Winamp play播放清單 Winamp
mht 網頁封存檔 Internet Explorer
mid 音樂檔 Media player
mov 影片檔 Quicktime
mp3 聲音檔 Media player
mpg 影片檔 Media player
msi 安裝檔 滑鼠點兩下執行
mv2 影片檔 PowerDVD
nrg 燒錄映像檔 Nero
ogg 聲音檔 Winamp
pcx 圖片檔 ACDsee, Photoshop等秀圖, 影像處理軟體
pdb 資料庫 Palm作業系統專用
pdf 文件檔 Acrobat Reader
php 網頁程式檔 Internet Explorer, 用記事本開啟編輯
pls mp3播放列表 Winamp
png 圖片檔 ACDsee, Photoshop等秀圖, 影像處理軟體
pot PowerPoint範本檔 PowerPoint
pps PowerPoint播放檔 僅限播放, 無法修改
ppt PowerPoint文件檔 PowerPoint
prc 可執行程式檔 Palm作業系統專用
psd 圖片檔 Photoshop專用的格式
pwl Windows密碼檔 存放Windows中各式密碼
ra 影片檔 Realplayer
ram 影片檔 Realplayer
rar 壓縮檔 WinRAR3.0
reg 登錄檔 滑鼠點兩下匯入或用記事本開啟編輯
rm 影片檔 Realplayer
rtf 文字檔 Word
sav 儲存檔 遊戲進度的記錄檔案
scr 螢幕保護程式檔 按滑鼠右鍵選擇安裝
sfv 檢查檔 FireSFV
swf 動畫檔 Flash
swp 系統置換檔 管理虛擬記憶體檔案, 勿隨意刪除
sys 系統檔 程式重要檔案, 勿隨意刪除
tab 輸入法的對照表 記事本
tar 壓縮檔 WinRAR3.0
tbl 輸入法字碼檔 輸入法所需使用的檔案
tga 圖片檔 ACDSee, Photoshop等秀圖, 影像處理軟體
tgz 壓縮檔 WinRAR 3.0
tif 圖片檔 ACDSee, Photoshop等秀圖, 影像處理軟體
tmp 暫存檔 程式視需要建立, 可刪除
ttf 字形檔 在控制台中的字型資料夾中新增
txt 文字檔 記事本, Word等可編輯文字的程式
uin ICQ使用者資訊檔 記錄ICQ號碼
url 網頁位址 Internet Explorer
vbs VB script檔 可用記事本開啟
vob 影片檔 PowerDVD
voc 聲音檔 Media player
wab 通訊錄檔 Outlook Express使用
wav 聲音檔 Media player
wbk Word備份檔 Word
wmf 聲音檔 Media player
wri 文件檔 小作家
wsz Winamp的外觀檔 用Winamp匯入
xls excel文件檔 Excel
xml 跨平台網頁檔 Internet Explorer
zip 壓縮檔 Winzip, WinRAR3.0
2007年11月10日
build.xml:61: Specify at least one source
nutch 版本:nutch-0.9 In cygwin shell
問題: 用ant直接compile遇到 build.xml:61: Specify at least one source 的error
solution: 把下面的codes 註解掉就解決

問題: 用ant直接compile遇到 build.xml:61: Specify at least one source 的error
solution: 把下面的codes 註解掉就解決

2007年11月8日

在cygwin下利用ssh機制傳檔
@硬體環境
本地端 (140.118.xxx.x7) /home/sausage/
服務端 (140.112.xx.xx9) /home/sausage/
@目地
生成的密鑰對id_rsa,id_rsa.pub,預設存儲在 本機端/home/sausage/.ssh目錄下。然后將id_rsa.pub的內容復制到每個機器(也包括本機)的/home/user_name/.ssh/authorized_keys文件中,如果機器上已經有authorized_keys這個文件了,就在文件末尾加上id_rsa.pub中的內容,如果沒有authorized_keys這個文件,直接cp或者scp就好了,下面的操作假設各個機器上都沒有authorized_keys文件。
@Steps:
1) 在本地端需要先建立一個密鑰對,即一個私鑰,一個公鑰。將公鑰拷貝到服務端 (140.112.x.x) /home/sausage/.ssh (.ssh自己建立)資料夾下

ps) command: ssh-keygen -t rsa
Enter file in which to save the key :採用預設值
Enter passphrase: 按enter(即空白為密碼)
2) 將id_rsa.pub的內容復制到每個機器(也包括本機)的/home/user_name/.ssh/authorized_keys 文件中
(a) 使用 scp 指令 可以使用 scp 指令來透過一個安全且加密的連線在機器間傳輸檔
案 , 就如同rcp指令。

(b)先將id_rsa.pub的內容復制到/home/user_name/.ssh/authorized_keys文件中

(c)再利用scp 指令傳檔

本地端 (140.118.xxx.x7) /home/sausage/
服務端 (140.112.xx.xx9) /home/sausage/
@目地
生成的密鑰對id_rsa,id_rsa.pub,預設存儲在 本機端/home/sausage/.ssh目錄下。然后將id_rsa.pub的內容復制到每個機器(也包括本機)的/home/user_name/.ssh/authorized_keys文件中,如果機器上已經有authorized_keys這個文件了,就在文件末尾加上id_rsa.pub中的內容,如果沒有authorized_keys這個文件,直接cp或者scp就好了,下面的操作假設各個機器上都沒有authorized_keys文件。
@Steps:
1) 在本地端需要先建立一個密鑰對,即一個私鑰,一個公鑰。將公鑰拷貝到服務端 (140.112.x.x) /home/sausage/.ssh (.ssh自己建立)資料夾下

ps) command: ssh-keygen -t rsa
Enter file in which to save the key :採用預設值
Enter passphrase: 按enter(即空白為密碼)
2) 將id_rsa.pub的內容復制到每個機器(也包括本機)的/home/user_name/.ssh/authorized_keys 文件中
(a) 使用 scp 指令 可以使用 scp 指令來透過一個安全且加密的連線在機器間傳輸檔
案 , 就如同rcp指令。

(b)先將id_rsa.pub的內容復制到/home/user_name/.ssh/authorized_keys文件中

(c)再利用scp 指令傳檔

Cygwin 中文顯示及color 設定
1) ~/.inputrc
取消註解以下幾行:
set meta-flag on
set convert-meta off
set input-meta on
set output-meta on
2) ~/.bashrc
加入以下資料:
alias ls='ls -hF --show-control-chars --color=tty'
=>要立即生效, 下command
source .inputrc 及 source .bashrc
取消註解以下幾行:
set meta-flag on
set convert-meta off
set input-meta on
set output-meta on
2) ~/.bashrc
加入以下資料:
alias ls='ls -hF --show-control-chars --color=tty'
=>要立即生效, 下command
source .inputrc 及 source .bashrc

在 Cygwin 下安裝 SSHD 的方式
安裝步驟
1)安裝 cygwin 時,套件中必須勾選:
Admin --> cygrunsrv
Net --> openssh
2)進入 Cygwin 並執行 ssh-host-config 指令:
privilege separation be used? (yes/no) no
Do you want to install sshd as service? yes
認證方式輸入預設 ntsec
3)啟動服務
cygrunsrv --start sshd
4)讓 sshd 隨著 Windows 一起啟動
cygrunsrv --install sshd
常用指令
@列出目前所安裝的服務
@啟動服務
cygrunsrv --start
@停止服務
cygrunsrv --stop
@安裝服務
cygrunsrv --install
@移除服務
cygrunsrv --remove
2007年11月6日
搜索引擎發展史
搜索引擎發展史
在互聯網發展初期,網站相對較少,資訊搜尋比較容易。然而伴隨互聯網爆炸性的發展,普通網絡使用者想找到所需的資料簡直如同大海撈針,這時為滿足大眾資訊檢索需求的專業搜索網站便應運而生了。
現代意義上的搜索引擎的祖先,是1990年由蒙特利爾大學學生Alan Emtage發明的Archie。雖然當時World Wide Web還未出現,但網絡中文件傳輸還是相當頻繁的,而且由於大量的文件散布在各個分散的FTP主電腦中,查詢起來非常不便,因此Alan Emtage想到了開發一個可以以文件名搜尋文件的系統,於是便有了Archie。
Archie工作原理與現在的搜索引擎已經很接近,它依靠腳本程序自動搜索網上的文件,然后對有關資訊進行索引,供使用者以一定的表達式查詢。由於Archie深受使用者歡迎,受其啟發,美國內華達System Computing Services大學於1993年開發了另一個與之非常相似的搜索工具,不過此時的搜索工具除了索引文件外,已能檢索網頁。
當時,“機器人”一詞在程式化者中十分流行。電腦“機器人”(Computer Robot)是指某個能以人類無法達到的速度不間斷地執行某項任務的軟體程序。由於專門用於檢索資訊的“機器人”程序象蜘蛛一樣在網絡間爬來爬去,因此,搜索引擎的“機器人”程序就被稱為“蜘蛛”程序。
世界上第一個用於監測互聯網發展規模的“機器人”程序是Matthew Gray開發的World wide Web Wanderer。剛開始它只用來統計互聯網上的服務器數量,后來則發展為能夠檢索網站域名。
與Wanderer相對應,Martin Koster於1993年10月創建了ALIWEB,它是Archie的HTTP版本。ALIWEB不使用“機器人”程序,而是靠網站主動提交資訊來建立自己的連結索引,類似於現在我們熟知的Yahoo。
隨著互聯網的迅速發展,使得檢索所有新出現的網頁變得越來越困難,因此,在Matthew Gray的Wanderer基礎上,一些程式化者將傳統的“蜘蛛”程序工作原理作了些改進。其設想是,既然所有網頁都可能有連向其他網站的連結,那麼從跟蹤一個網站的連結開始,就有可能檢索整個互聯網。到1993年底,一些基於此原理的搜索引擎開始紛紛涌現,其中以JumpStation、The World Wide Web Worm(Goto的前身,也就是今天Overture),和Repository-Based Software Engineering (RBSE) spider最負盛名。
然而JumpStation和WWW Worm只是以搜索工具在資料庫中找到匹配資訊的先后次序排列搜索結果,因此毫無資訊關聯度可言。而RBSE是第一個在搜索結果排列中引入關鍵字串匹配程度概念的引擎。
最早現代意義上的搜索引擎出現於1994年7月。當時Michael Mauldin將John Leavitt的蜘蛛程序接入到其索引程序中,創建了大家現在熟知的Lycos。同年4月,斯坦福(Stanford)大學的兩名博士生,David Filo和美籍華人楊致遠(Gerry Yang)共同創辦了超級目錄索引Yahoo,並成功地使搜索引擎的概念深入人心。從此搜索引擎進入了高速發展時期。目前,互聯網上有名有姓的搜索引擎已達數百家,其檢索的資訊量也與從前不可同日而語。比如最近風頭正勁的Google,其資料庫中存放的網頁已達30億之巨!
隨著互聯網規模的急劇膨脹,一家搜索引擎光靠自己單打獨斗已無法適應目前的市場狀況,因此現在搜索引擎之間開始出現了分工協作,並有了專業的搜索引擎技術和搜索資料庫服務提供商。象國外的Inktomi(已被Yahoo收購),它本身並不是直接面向使用者的搜索引擎,但向包括Overture(原GoTo,已被Yahoo收購)、LookSmart、MSN、HotBot等在內的其他搜索引擎提供全文網頁搜索服務。國內的百度也屬於這一類(注1),搜狐和新浪用的就是它的技術(注2)。因此從這個意義上說,它們是搜索引擎的搜索引擎。
(注1):百度已於2001年9月開始提供公共搜索服務。
(注1):搜狐二級網頁搜索現已改為中搜的引擎,而新浪則已轉用Google的搜索結果。
搜索引擎分類
搜索引擎按其工作方式主要可分為三種,分別是全文搜索引擎(Full Text Search Engine)、目錄索引類搜索引擎(Search Index/Directory)和元搜索引擎(Meta Search Engine)。
■ 全文搜索引擎
全文搜索引擎是名副其實的搜索引擎,國外具代表性的有Google、Fast/AllTheWeb、AltaVista、Inktomi、Teoma、WiseNut等,國內著名的有百度(Baidu)。它們都是通過從互聯網上提取的各個網站的資訊(以網頁文字為主)而建立的資料庫中,檢索與使用者查詢條件匹配的相關記錄,然后按一定的排列順序將結果返回給使用者,因此他們是真正的搜索引擎。 從搜索結果來源的角度,全文搜索引擎又可細分為兩種,一種是擁有自己的檢索程序(Indexer),俗稱“蜘蛛”(Spider)程序或“機器人”(Robot)程序,並自建網頁資料庫,搜索結果直接從自身的資料庫中調用,如上面提到的7家引擎;另一種則是租用其他引擎的資料庫,並按自定的格式排列搜索結果,如Lycos引擎。
■ 目錄索引
目錄索引雖然有搜索功能,但在嚴格意義上算不上是真正的搜索引擎,僅僅是按目錄分類的網站連結列表而已。使用者完全可以不用進行關鍵詞(Keywords)查詢,僅靠分類目錄也可找到需要的資訊。目錄索引中最具代表性的莫過於大名鼎鼎的Yahoo雅虎。其他著名的還有Open Directory Project(DMOZ)、LookSmart、About等。國內的搜狐、新浪、網易搜索也都屬於這一類。
■ 元搜索引擎 (META Search Engine)
元搜索引擎在接受使用者查詢請求時,同時在其他多個引擎上進行搜索,並將結果返回給使用者。著名的元搜索引擎有InfoSpace、Dogpile、Vivisimo等(元搜索引擎列表),中文元搜索引擎中具代表性的有搜星搜索引擎。在搜索結果排列方面,有的直接按來源引擎排列搜索結果,如Dogpile,有的則按自定的規則將結果重新排列組合,如Vivisimo。
除上述三大類引擎外,還有以下幾種非主流形式:
1、集合式搜索引擎:如HotBot在2002年底推出的引擎。該引擎類似META搜索引擎,但區別在於不是同時調用多個引擎進行搜索,而是由使用者從提供的4個引擎當中選擇,因此叫它“集合式”搜索引擎更確切些。
2、門戶搜索引擎:如AOL Search、MSN Search等雖然提供搜索服務,但自身即沒有分類目錄也沒有網頁資料庫,其搜索結果完全來自其他引擎。
3、免費連結列表(Free For All Links,簡稱FFA):這類網站一般只簡單地捲動排列連結條目,少部分有簡單的分類目錄,不過規模比起Yahoo等目錄索引來要小得多。
由於上述網站都為使用者提供搜索查詢服務,為方便起見,我們通常將其統稱為搜索引擎。搜索引擎基本工作原理了解搜索引擎的工作原理對我們日常搜索應用和網站提交推廣都會有很大幫助。
■ 全文搜索引擎
在搜索引擎分類部分我們提到過全文搜索引擎從網站提取資訊建立網頁資料庫的概念。搜索引擎的自動資訊搜集功能分兩種。一種是定期搜索,即每隔一段時間(比如Google一般是28天),搜索引擎主動派出“蜘蛛”程序,對一定IP地址範圍內的互聯網站進行檢索,一旦發現新的網站,它會自動提取網站的資訊和網址加入自己的資料庫。 另一種是提交網站搜索,即網站擁有者主動向搜索引擎提交網址,它在一定時間內(2天到數月不等)定向向你的網站派出“蜘蛛”程序,掃瞄你的網站並將有關資訊存入資料庫,以備使用者查詢。由於近年來搜索引擎索引規則發生了很大變化,主動提交網址並不保證你的網站能進入搜索引擎資料庫,因此目前最好的辦法是多獲得一些外部連結,讓搜索引擎有更多機會找到你並自動將你的網站收錄。 當使用者以關鍵詞搜尋資訊時,搜索引擎會在資料庫中進行搜尋,如果找到與使用者要求內容相符的網站,便採用特殊的算法——通常根據網頁中關鍵詞的匹配程度,出現的位置/頻次,連結質量等——計算出各網頁的相關度及排名等級,然后根據關聯度高低,按順序將這些網頁連結返回給使用者。
........................................................................................
■ 目錄索引
與全文搜索引擎相比,目錄索引有許多不同之處。
首先,搜索引擎屬於自動網站檢索,而目錄索引則完全依賴手工操作。使用者提交網站后,目錄編輯人員會親自瀏覽你的網站,然后根據一套自定的評判標準甚至編輯人員的主觀印象,決定是否接納你的網站。
其次,搜索引擎收錄網站時,只要網站本身沒有違反有關的規則,一般都能登錄成功。而目錄索引對網站的要求則高得多,有時即使登錄多次也不一定成功。尤其象Yahoo!這樣的超級索引,登錄更是困難。(由於登錄Yahoo!的難度最大,而它又是商家必爭之地,所以我們會在后面用專門的篇幅介紹登錄Yahoo雅虎的技巧)
此外,在登錄搜索引擎時,我們一般不用考慮網站的分類問題,而登錄目錄索引時則必須將網站放在一個最合適的目錄(Directory)。
最后,搜索引擎中各網站的有關資訊都是從使用者網頁中自動提取的,所以使用者的角度看,我們擁有更多的自主權;而目錄索引則要求必須手工另外填寫網站資訊,而且還有各種各樣的限制。更有甚者,如果工作人員認為你提交網站的目錄、網站資訊不合適,他可以隨時對其進行調整,當然事先是不會和你商量的。
目錄索引,顧名思義就是將網站分門別類地存放在相應的目錄中,因此使用者在查詢資訊時,可選擇關鍵詞搜索,也可按分類目錄逐層搜尋。如以關鍵詞搜索,返回的結果跟搜索引擎一樣,也是根據資訊關聯程度排列網站,只不過其中人為因素要多一些。如果按分層目錄搜尋,某一目錄中網站的排名則是由標題字母的先后順序決定(也有例外)。
目前,搜索引擎與目錄索引有相互融合滲透的趨勢。原來一些純粹的全文搜索引擎現在也提供目錄搜索,如Google就借用Open Directory目錄提供分類查詢。而象 Yahoo! 這些老牌目錄索引則通過與Google等搜索引擎合作擴大搜索範圍
(注)。在預設搜索模式下,一些目錄類搜索引擎首先返回的是自己目錄中匹配的網站,如國內搜狐、新浪、網易等;而另外一些則預設的是網頁搜索,如Yahoo。
(注):Yahoo已於2004年2月正式推出自己的全文搜索引擎,並結束了與Google的合作。
在互聯網發展初期,網站相對較少,資訊搜尋比較容易。然而伴隨互聯網爆炸性的發展,普通網絡使用者想找到所需的資料簡直如同大海撈針,這時為滿足大眾資訊檢索需求的專業搜索網站便應運而生了。
現代意義上的搜索引擎的祖先,是1990年由蒙特利爾大學學生Alan Emtage發明的Archie。雖然當時World Wide Web還未出現,但網絡中文件傳輸還是相當頻繁的,而且由於大量的文件散布在各個分散的FTP主電腦中,查詢起來非常不便,因此Alan Emtage想到了開發一個可以以文件名搜尋文件的系統,於是便有了Archie。
Archie工作原理與現在的搜索引擎已經很接近,它依靠腳本程序自動搜索網上的文件,然后對有關資訊進行索引,供使用者以一定的表達式查詢。由於Archie深受使用者歡迎,受其啟發,美國內華達System Computing Services大學於1993年開發了另一個與之非常相似的搜索工具,不過此時的搜索工具除了索引文件外,已能檢索網頁。
當時,“機器人”一詞在程式化者中十分流行。電腦“機器人”(Computer Robot)是指某個能以人類無法達到的速度不間斷地執行某項任務的軟體程序。由於專門用於檢索資訊的“機器人”程序象蜘蛛一樣在網絡間爬來爬去,因此,搜索引擎的“機器人”程序就被稱為“蜘蛛”程序。
世界上第一個用於監測互聯網發展規模的“機器人”程序是Matthew Gray開發的World wide Web Wanderer。剛開始它只用來統計互聯網上的服務器數量,后來則發展為能夠檢索網站域名。
與Wanderer相對應,Martin Koster於1993年10月創建了ALIWEB,它是Archie的HTTP版本。ALIWEB不使用“機器人”程序,而是靠網站主動提交資訊來建立自己的連結索引,類似於現在我們熟知的Yahoo。
隨著互聯網的迅速發展,使得檢索所有新出現的網頁變得越來越困難,因此,在Matthew Gray的Wanderer基礎上,一些程式化者將傳統的“蜘蛛”程序工作原理作了些改進。其設想是,既然所有網頁都可能有連向其他網站的連結,那麼從跟蹤一個網站的連結開始,就有可能檢索整個互聯網。到1993年底,一些基於此原理的搜索引擎開始紛紛涌現,其中以JumpStation、The World Wide Web Worm(Goto的前身,也就是今天Overture),和Repository-Based Software Engineering (RBSE) spider最負盛名。
然而JumpStation和WWW Worm只是以搜索工具在資料庫中找到匹配資訊的先后次序排列搜索結果,因此毫無資訊關聯度可言。而RBSE是第一個在搜索結果排列中引入關鍵字串匹配程度概念的引擎。
最早現代意義上的搜索引擎出現於1994年7月。當時Michael Mauldin將John Leavitt的蜘蛛程序接入到其索引程序中,創建了大家現在熟知的Lycos。同年4月,斯坦福(Stanford)大學的兩名博士生,David Filo和美籍華人楊致遠(Gerry Yang)共同創辦了超級目錄索引Yahoo,並成功地使搜索引擎的概念深入人心。從此搜索引擎進入了高速發展時期。目前,互聯網上有名有姓的搜索引擎已達數百家,其檢索的資訊量也與從前不可同日而語。比如最近風頭正勁的Google,其資料庫中存放的網頁已達30億之巨!
隨著互聯網規模的急劇膨脹,一家搜索引擎光靠自己單打獨斗已無法適應目前的市場狀況,因此現在搜索引擎之間開始出現了分工協作,並有了專業的搜索引擎技術和搜索資料庫服務提供商。象國外的Inktomi(已被Yahoo收購),它本身並不是直接面向使用者的搜索引擎,但向包括Overture(原GoTo,已被Yahoo收購)、LookSmart、MSN、HotBot等在內的其他搜索引擎提供全文網頁搜索服務。國內的百度也屬於這一類(注1),搜狐和新浪用的就是它的技術(注2)。因此從這個意義上說,它們是搜索引擎的搜索引擎。
(注1):百度已於2001年9月開始提供公共搜索服務。
(注1):搜狐二級網頁搜索現已改為中搜的引擎,而新浪則已轉用Google的搜索結果。
搜索引擎分類
搜索引擎按其工作方式主要可分為三種,分別是全文搜索引擎(Full Text Search Engine)、目錄索引類搜索引擎(Search Index/Directory)和元搜索引擎(Meta Search Engine)。
■ 全文搜索引擎
全文搜索引擎是名副其實的搜索引擎,國外具代表性的有Google、Fast/AllTheWeb、AltaVista、Inktomi、Teoma、WiseNut等,國內著名的有百度(Baidu)。它們都是通過從互聯網上提取的各個網站的資訊(以網頁文字為主)而建立的資料庫中,檢索與使用者查詢條件匹配的相關記錄,然后按一定的排列順序將結果返回給使用者,因此他們是真正的搜索引擎。 從搜索結果來源的角度,全文搜索引擎又可細分為兩種,一種是擁有自己的檢索程序(Indexer),俗稱“蜘蛛”(Spider)程序或“機器人”(Robot)程序,並自建網頁資料庫,搜索結果直接從自身的資料庫中調用,如上面提到的7家引擎;另一種則是租用其他引擎的資料庫,並按自定的格式排列搜索結果,如Lycos引擎。
■ 目錄索引
目錄索引雖然有搜索功能,但在嚴格意義上算不上是真正的搜索引擎,僅僅是按目錄分類的網站連結列表而已。使用者完全可以不用進行關鍵詞(Keywords)查詢,僅靠分類目錄也可找到需要的資訊。目錄索引中最具代表性的莫過於大名鼎鼎的Yahoo雅虎。其他著名的還有Open Directory Project(DMOZ)、LookSmart、About等。國內的搜狐、新浪、網易搜索也都屬於這一類。
■ 元搜索引擎 (META Search Engine)
元搜索引擎在接受使用者查詢請求時,同時在其他多個引擎上進行搜索,並將結果返回給使用者。著名的元搜索引擎有InfoSpace、Dogpile、Vivisimo等(元搜索引擎列表),中文元搜索引擎中具代表性的有搜星搜索引擎。在搜索結果排列方面,有的直接按來源引擎排列搜索結果,如Dogpile,有的則按自定的規則將結果重新排列組合,如Vivisimo。
除上述三大類引擎外,還有以下幾種非主流形式:
1、集合式搜索引擎:如HotBot在2002年底推出的引擎。該引擎類似META搜索引擎,但區別在於不是同時調用多個引擎進行搜索,而是由使用者從提供的4個引擎當中選擇,因此叫它“集合式”搜索引擎更確切些。
2、門戶搜索引擎:如AOL Search、MSN Search等雖然提供搜索服務,但自身即沒有分類目錄也沒有網頁資料庫,其搜索結果完全來自其他引擎。
3、免費連結列表(Free For All Links,簡稱FFA):這類網站一般只簡單地捲動排列連結條目,少部分有簡單的分類目錄,不過規模比起Yahoo等目錄索引來要小得多。
由於上述網站都為使用者提供搜索查詢服務,為方便起見,我們通常將其統稱為搜索引擎。搜索引擎基本工作原理了解搜索引擎的工作原理對我們日常搜索應用和網站提交推廣都會有很大幫助。
■ 全文搜索引擎
在搜索引擎分類部分我們提到過全文搜索引擎從網站提取資訊建立網頁資料庫的概念。搜索引擎的自動資訊搜集功能分兩種。一種是定期搜索,即每隔一段時間(比如Google一般是28天),搜索引擎主動派出“蜘蛛”程序,對一定IP地址範圍內的互聯網站進行檢索,一旦發現新的網站,它會自動提取網站的資訊和網址加入自己的資料庫。 另一種是提交網站搜索,即網站擁有者主動向搜索引擎提交網址,它在一定時間內(2天到數月不等)定向向你的網站派出“蜘蛛”程序,掃瞄你的網站並將有關資訊存入資料庫,以備使用者查詢。由於近年來搜索引擎索引規則發生了很大變化,主動提交網址並不保證你的網站能進入搜索引擎資料庫,因此目前最好的辦法是多獲得一些外部連結,讓搜索引擎有更多機會找到你並自動將你的網站收錄。 當使用者以關鍵詞搜尋資訊時,搜索引擎會在資料庫中進行搜尋,如果找到與使用者要求內容相符的網站,便採用特殊的算法——通常根據網頁中關鍵詞的匹配程度,出現的位置/頻次,連結質量等——計算出各網頁的相關度及排名等級,然后根據關聯度高低,按順序將這些網頁連結返回給使用者。
........................................................................................
■ 目錄索引
與全文搜索引擎相比,目錄索引有許多不同之處。
首先,搜索引擎屬於自動網站檢索,而目錄索引則完全依賴手工操作。使用者提交網站后,目錄編輯人員會親自瀏覽你的網站,然后根據一套自定的評判標準甚至編輯人員的主觀印象,決定是否接納你的網站。
其次,搜索引擎收錄網站時,只要網站本身沒有違反有關的規則,一般都能登錄成功。而目錄索引對網站的要求則高得多,有時即使登錄多次也不一定成功。尤其象Yahoo!這樣的超級索引,登錄更是困難。(由於登錄Yahoo!的難度最大,而它又是商家必爭之地,所以我們會在后面用專門的篇幅介紹登錄Yahoo雅虎的技巧)
此外,在登錄搜索引擎時,我們一般不用考慮網站的分類問題,而登錄目錄索引時則必須將網站放在一個最合適的目錄(Directory)。
最后,搜索引擎中各網站的有關資訊都是從使用者網頁中自動提取的,所以使用者的角度看,我們擁有更多的自主權;而目錄索引則要求必須手工另外填寫網站資訊,而且還有各種各樣的限制。更有甚者,如果工作人員認為你提交網站的目錄、網站資訊不合適,他可以隨時對其進行調整,當然事先是不會和你商量的。
目錄索引,顧名思義就是將網站分門別類地存放在相應的目錄中,因此使用者在查詢資訊時,可選擇關鍵詞搜索,也可按分類目錄逐層搜尋。如以關鍵詞搜索,返回的結果跟搜索引擎一樣,也是根據資訊關聯程度排列網站,只不過其中人為因素要多一些。如果按分層目錄搜尋,某一目錄中網站的排名則是由標題字母的先后順序決定(也有例外)。
目前,搜索引擎與目錄索引有相互融合滲透的趨勢。原來一些純粹的全文搜索引擎現在也提供目錄搜索,如Google就借用Open Directory目錄提供分類查詢。而象 Yahoo! 這些老牌目錄索引則通過與Google等搜索引擎合作擴大搜索範圍
(注)。在預設搜索模式下,一些目錄類搜索引擎首先返回的是自己目錄中匹配的網站,如國內搜狐、新浪、網易等;而另外一些則預設的是網頁搜索,如Yahoo。
(注):Yahoo已於2004年2月正式推出自己的全文搜索引擎,並結束了與Google的合作。
2007年11月5日
byte 陣列以及 char 陣列,轉成String型態
以ACCII編碼來看,假設我有一byte陣列如下:
我要如何把testbyte這個陣列改為String型態,而且String即為"test"?
==>
----------------------------------------------------------
同樣的,假設我有一char陣列如下:
我要如何把testchar這個陣列改為String型態,而且String即為"test"?
==>
byte[] testbyte = new byte[4];
testbyte[0] = 116; //116,ACCII編碼為t
testbyte[1] = 101; //101,ACCII編碼為e
testbyte[2] = 115; //115,ACCII編碼為s
testbyte[3] = 116; //116,ACCII編碼為t
我要如何把testbyte這個陣列改為String型態,而且String即為"test"?
==>
class strTest2
{
public static void main(String[] args)
{
byte[] testbyte = new byte[4];
testbyte[0] = 116;
testbyte[1] = 101;
testbyte[2] = 115;
testbyte[3] = 116;
String str = new String(testbyte);
System.out.println(str);
}
}
----------------------------------------------------------
同樣的,假設我有一char陣列如下:
char[] testchar = new char[4];
testchar[0] = 't';
testchar[1] = 'e';
testchar[2] = 's';
testchar[3] = 't';
我要如何把testchar這個陣列改為String型態,而且String即為"test"?
==>
class strTest
{
public static void main(String[] args)
{
char[] testchar = new char[4];
testchar[0] = 't';
testchar[1] = 'e';
testchar[2] = 's';
testchar[3] = 't';
String str = new String(testchar);
System.out.println(str);
}
}
2007年11月2日
Nutch API
Run on cygwin
(1) Command : bin/nutch readdb
目的 :讀取 或 轉存 Crawl Database(crawldb) 內部資訊
Example : 在nutch目錄下下command
Command (a) bin/nutch readdb Test10/crawldb -stats (結果如下)

Command (b) bin/nutch readdb Test10/crawldb -dump dump_dir
-->把crawldb 內的資料dump到dump_dir資料夾底下,內部資料如下

(1) Command : bin/nutch readdb
目的 :讀取 或 轉存 Crawl Database(crawldb) 內部資訊
Example : 在nutch目錄下下command
Command (a) bin/nutch readdb Test10/crawldb -stats (結果如下)

Command (b) bin/nutch readdb Test10/crawldb -dump dump_dir
-->把crawldb 內的資料dump到dump_dir資料夾底下,內部資料如下

-->針對 某個已經抓取到的網址 show 出此網址相關資料
Nutch Environment
Nutch-0.9
Tomcat-5.5
JRE-1.6.0_02
Jdk-1.6
Hadoop-0.14.2
Run onWin32, cygwin, for shell support
Tomcat-5.5
JRE-1.6.0_02
Jdk-1.6
Hadoop-0.14.2
Run onWin32, cygwin, for shell support
2007年10月30日
2007年10月26日
About Nutch
Nutch 是一個開源Java 實現的搜索引擎。它提供了我們運行自己的搜索引擎所需的全部工具。可以為什麼我們需要建立自己的搜索引擎呢?畢竟我們已經有google可以使用。這里我列出3點原因:
(1)透明度:Nutch是開放源代碼的,因此任何人都可以查看他的排序算法是如何工作的。商業的搜索引擎排序算法都是保密的,我們無法知道為什麼搜索出來的排序結果是如何算出來的。更進一步,一些搜索引擎允許競價排名,比如百度,這樣的索引結果並不是和站台內容相關的。因此 Nutch 對學術搜索和政府類站台的搜索來說,是個好選擇。因為一個公平的排序結果是非常重要的。
對搜索引擎的理解:我們並沒有google的源代碼,因此學習搜索引擎Nutch是個不錯的選擇。了解一個大型分布式的搜索引擎如何工作是一件讓人很受益的事情。在寫Nutch的過程中,從學院派和工業派借鑒了很多知識:比如:Nutch的核心部分目前已經被重新用 Map Reduce 實現了。看過開復演講的人都知道 Map Reduce 的一點知識吧。Map Reduce 是一個分布式的處理模型,最先是從 Google 實驗室提出來的。你也可以從下面獲得更多的消息。
http://www.domolo.com/bbs/list.asp?boardid=29
http://domolo.oicp.net/bbs/list.asp?boardid=29
並且 Nutch 也吸引了很多研究者,他們非常樂於嘗試新的搜索算法,因為對Nutch 來說,這是非常容易實現擴展的。
(2)擴展性:你是不是不喜歡其他的搜索引擎展現結果的方式呢?那就用 Nutch 寫你自己的搜索引擎吧。
(3)Nutch 是非常靈活的:他可以被很好的客戶訂制並集成到你的應用程序中:使用Nutch 的外掛程式機制,Nutch 可以作為一個搜索不同資訊載體的搜索平台。當然,最簡單的就是集成Nutch到你的站台,為你的使用者提供搜索服務。
Nutch 的安裝分為3個層次:基於本地文件系統,基於局域網,或者基於 internet 。不同的安裝方式具有不同的特色。比如:索引一個本地文件系統相對於其他兩個來說肯定是要穩定多了,因為沒有 網絡錯誤也不同緩存文件的拷貝。基於Internet 的搜索又是另一個極端:抓取數以千計的網頁有很多技術問題需要解決:我們從哪些頁面開始抓取?我們如何分配抓取工作?何時需要重新抓取?我們如何解決失效的連結,沒有響應的站台和重復的內容?還有如何解決對大型資料的上百個並發訪問?搭建這樣一個搜索引擎是一筆不小的投資呀!在 " Building Nutch: Open Source Search," 的作者 Mike Cafarella 和 Doug Cutting 總結如下:
: ... 一個具有完全功能的搜索系統:1億頁面索引量,每秒2個並發索引,需要每月800美元。10億頁面索引量,每秒50個頁面請求,大概需要每月30000美元。
這篇文章將為你演示如何在中等級別的網站上搭建Nutch。第一部分集中在抓取上。Nutch的抓取架構,如何運行一個抓取程序,理解這個抓取過程產生了什麼。第二部分關注搜索。演示如何運行Nutch搜索程序。以及如何訂制Nutch 。
Nutch Vs. Lucene
Nutch 是基於 Lucene的。Lucene為 Nutch 提供了文本索引和搜索的API。一個常見的問題是;我應該使用Lucene還是Nutch?最簡單的回答是:如果你不需要抓取資料的話,應該使用Lucene。常見的應用場合是:你有資料源,需要為這些資料提供一個搜索頁面。在這種情況下,最好的方式是直接從資料庫中取出資料並用Lucene API建立索引。中文使用者,可以參考 WebLucene 或者 車東 的一些列文章。如果需要中文分詞幫助還可以聯系作者。
http://domolo.oicp.net/bbs/list.asp?boardid=24
Erik Hatcher 和 Otis Gospodnetić's 的 Lucene in Action 中詳細講述了這個過程。Nutch 適用於你無法直接獲取資料庫中的網站,或者比較分散的資料源的情況下使用。
架構
總體上Nutch可以分為2個部分:抓取部分和搜索部分。抓取程序抓取頁面並把抓取回來的資料做成反向索引,搜索程序則對反向索引搜索回答使用者的請求。抓取程序和搜索程序的接口是索引。兩者都使用索引中的字段。()
實際上搜索程序和抓取程序可以分別位於不同的機器上。()
這里我們先看看Nutch的抓取部分。
抓取程序: 抓取程序是被Nutch的抓取工具驅動的。這是一組工具,用來建立和維護幾個不同的資料結構: web database, a set of segments, and the index。下面我們逐個解釋上面提到的3個不同的資料結構。
The web database, 或者WebDB, 是一個特殊存儲資料結構,用來映像被抓取網站資料的結構和屬性的集合。WebDB 用來存儲從抓取開始(包括重新抓取)的所有網站結構資料和屬性。WebDB 只是被 抓取程序使用,搜索程序並不使用它。WebDB 存儲2種實體:頁面 和 連結。頁面 表示 網絡上的一個網頁,這個網頁的Url作為標示被索引,同時建立一個對網頁內容的MD5 哈希簽名。跟網頁相關的其它內容也被存儲,包括:頁面中的連結數量(外連結),頁面抓取資訊(在頁面被重復抓取的情況下),還有表示頁面級別的分數 score 。連結 表示從一個網頁的連結到其它網頁的連結。因此 WebDB 可以說是一個網絡圖,節點是頁面,連結是邊。
Segment 是 網頁 的集合,並且它被索引。 Segment 的 Fetchlist 是抓取程序使用的 url 列表 , 它是從 WebDB中生成的。Fetcher 的輸出資料是從 fetchlist 中抓取的網頁。Fetcher 的輸出資料先被反向索引,然后索引后的結果被存儲在segment 中。 Segment 的生命周期是有限制的,當下一輪抓取開始后它就沒有用了。預設的 重新抓取間隔是30天。因此刪除超過這個時間期限的segment是可以的。而且也可以節省不少磁盤空間。Segment 的命名是 日期加時間 ,因此很直觀的可以看出他們的存活周期。
索引庫 是 反向索引所有系統中被抓取的頁面,他並不直接從頁面反向索引產生,它是合並很多小的 segment 的索引中產生的。Nutch 使用 Lucene 來建立索引,因此所有 Lucene 相關的工具 API 都用來建立索引庫。需要說明的是 Lucene 的 segment 的概念 和 Nutch 的 segment 概念是完全不同的,不要混淆哦。 可以參考 車東 的相關文章。 www.chedong.com 簡單來說 Lucene 的 segment 是 Lucene 索引庫的一部分,而 Nutch 的 Segment 是 WebDB 中 被 抓取和索引的一部分
(1)透明度:Nutch是開放源代碼的,因此任何人都可以查看他的排序算法是如何工作的。商業的搜索引擎排序算法都是保密的,我們無法知道為什麼搜索出來的排序結果是如何算出來的。更進一步,一些搜索引擎允許競價排名,比如百度,這樣的索引結果並不是和站台內容相關的。因此 Nutch 對學術搜索和政府類站台的搜索來說,是個好選擇。因為一個公平的排序結果是非常重要的。
對搜索引擎的理解:我們並沒有google的源代碼,因此學習搜索引擎Nutch是個不錯的選擇。了解一個大型分布式的搜索引擎如何工作是一件讓人很受益的事情。在寫Nutch的過程中,從學院派和工業派借鑒了很多知識:比如:Nutch的核心部分目前已經被重新用 Map Reduce 實現了。看過開復演講的人都知道 Map Reduce 的一點知識吧。Map Reduce 是一個分布式的處理模型,最先是從 Google 實驗室提出來的。你也可以從下面獲得更多的消息。
http://www.domolo.com/bbs/list.asp?boardid=29
http://domolo.oicp.net/bbs/list.asp?boardid=29
並且 Nutch 也吸引了很多研究者,他們非常樂於嘗試新的搜索算法,因為對Nutch 來說,這是非常容易實現擴展的。
(2)擴展性:你是不是不喜歡其他的搜索引擎展現結果的方式呢?那就用 Nutch 寫你自己的搜索引擎吧。
(3)Nutch 是非常靈活的:他可以被很好的客戶訂制並集成到你的應用程序中:使用Nutch 的外掛程式機制,Nutch 可以作為一個搜索不同資訊載體的搜索平台。當然,最簡單的就是集成Nutch到你的站台,為你的使用者提供搜索服務。
Nutch 的安裝分為3個層次:基於本地文件系統,基於局域網,或者基於 internet 。不同的安裝方式具有不同的特色。比如:索引一個本地文件系統相對於其他兩個來說肯定是要穩定多了,因為沒有 網絡錯誤也不同緩存文件的拷貝。基於Internet 的搜索又是另一個極端:抓取數以千計的網頁有很多技術問題需要解決:我們從哪些頁面開始抓取?我們如何分配抓取工作?何時需要重新抓取?我們如何解決失效的連結,沒有響應的站台和重復的內容?還有如何解決對大型資料的上百個並發訪問?搭建這樣一個搜索引擎是一筆不小的投資呀!在 " Building Nutch: Open Source Search," 的作者 Mike Cafarella 和 Doug Cutting 總結如下:
: ... 一個具有完全功能的搜索系統:1億頁面索引量,每秒2個並發索引,需要每月800美元。10億頁面索引量,每秒50個頁面請求,大概需要每月30000美元。
這篇文章將為你演示如何在中等級別的網站上搭建Nutch。第一部分集中在抓取上。Nutch的抓取架構,如何運行一個抓取程序,理解這個抓取過程產生了什麼。第二部分關注搜索。演示如何運行Nutch搜索程序。以及如何訂制Nutch 。
Nutch Vs. Lucene
Nutch 是基於 Lucene的。Lucene為 Nutch 提供了文本索引和搜索的API。一個常見的問題是;我應該使用Lucene還是Nutch?最簡單的回答是:如果你不需要抓取資料的話,應該使用Lucene。常見的應用場合是:你有資料源,需要為這些資料提供一個搜索頁面。在這種情況下,最好的方式是直接從資料庫中取出資料並用Lucene API建立索引。中文使用者,可以參考 WebLucene 或者 車東 的一些列文章。如果需要中文分詞幫助還可以聯系作者。
http://domolo.oicp.net/bbs/list.asp?boardid=24
Erik Hatcher 和 Otis Gospodnetić's 的 Lucene in Action 中詳細講述了這個過程。Nutch 適用於你無法直接獲取資料庫中的網站,或者比較分散的資料源的情況下使用。
架構
總體上Nutch可以分為2個部分:抓取部分和搜索部分。抓取程序抓取頁面並把抓取回來的資料做成反向索引,搜索程序則對反向索引搜索回答使用者的請求。抓取程序和搜索程序的接口是索引。兩者都使用索引中的字段。()
實際上搜索程序和抓取程序可以分別位於不同的機器上。()
這里我們先看看Nutch的抓取部分。
抓取程序: 抓取程序是被Nutch的抓取工具驅動的。這是一組工具,用來建立和維護幾個不同的資料結構: web database, a set of segments, and the index。下面我們逐個解釋上面提到的3個不同的資料結構。
The web database, 或者WebDB, 是一個特殊存儲資料結構,用來映像被抓取網站資料的結構和屬性的集合。WebDB 用來存儲從抓取開始(包括重新抓取)的所有網站結構資料和屬性。WebDB 只是被 抓取程序使用,搜索程序並不使用它。WebDB 存儲2種實體:頁面 和 連結。頁面 表示 網絡上的一個網頁,這個網頁的Url作為標示被索引,同時建立一個對網頁內容的MD5 哈希簽名。跟網頁相關的其它內容也被存儲,包括:頁面中的連結數量(外連結),頁面抓取資訊(在頁面被重復抓取的情況下),還有表示頁面級別的分數 score 。連結 表示從一個網頁的連結到其它網頁的連結。因此 WebDB 可以說是一個網絡圖,節點是頁面,連結是邊。
Segment 是 網頁 的集合,並且它被索引。 Segment 的 Fetchlist 是抓取程序使用的 url 列表 , 它是從 WebDB中生成的。Fetcher 的輸出資料是從 fetchlist 中抓取的網頁。Fetcher 的輸出資料先被反向索引,然后索引后的結果被存儲在segment 中。 Segment 的生命周期是有限制的,當下一輪抓取開始后它就沒有用了。預設的 重新抓取間隔是30天。因此刪除超過這個時間期限的segment是可以的。而且也可以節省不少磁盤空間。Segment 的命名是 日期加時間 ,因此很直觀的可以看出他們的存活周期。
索引庫 是 反向索引所有系統中被抓取的頁面,他並不直接從頁面反向索引產生,它是合並很多小的 segment 的索引中產生的。Nutch 使用 Lucene 來建立索引,因此所有 Lucene 相關的工具 API 都用來建立索引庫。需要說明的是 Lucene 的 segment 的概念 和 Nutch 的 segment 概念是完全不同的,不要混淆哦。 可以參考 車東 的相關文章。 www.chedong.com 簡單來說 Lucene 的 segment 是 Lucene 索引庫的一部分,而 Nutch 的 Segment 是 WebDB 中 被 抓取和索引的一部分
2007年10月24日
nutch 搜索中文會出現亂碼的問題
這個問題其實和 Nutch 關係不大,主要原因是使用 Tomcat 5.0 的問題。解決辦法是修改 Tomcat 的 server.xml 文件的connnector:
--
<-Connector port="8080"
maxThreads="150" minSpareThreads="25" maxSpareThreads="75"
enableLookups="false" redirectPort="8443" acceptCount="100"
connectionTimeout="20000" disableUploadTimeout="true"
URIEncoding="UTF-8" useBodyEncodingForURI="true" />
其中 URIEncoding="UTF-8" useBodyEncodingForURI="true" 是需要新增的。否則搜索欄輸入的字符預設編碼將不能正確解析。
2007年10月21日
Installing the JavaFX Script Plugin
Once you have configured the NetBeans Update Center Beta, you can now download and install the JavaFX Script plugin using the steps below.
(1) Select Tools > Update Center from the main menu of the IDE.
(2) In the Select Location of Modules page, select the NetBeans Update Center Beta check box and unselect all other checkboxes.

(3) Click Next and the wizard checks for any available updates for the plugin.
(4) In the Select Modules to Install page, select the four JavaFX Features nodes and click Add.

(5) Click Next.
(6) Click Accept in the License Agreement dialogs. The Download Modules page appears and progress is shown as the modules are downloaded.
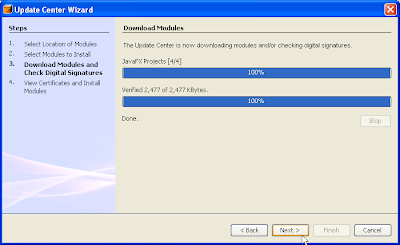
(7) Click Next after the modules have been successfully downloaded.The View Certificate and Install Modules page is displayed list of certificates are made available for your viewing.
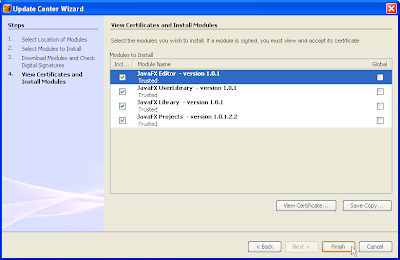
(8) Click Finish to proceed with the installation of the JavaFX plugin modules.The IDE proceeds with the installation.
(9) From the main menu, click Tools > Module Manager.The JavaFX Editor, JavaFX Projects, and JavaFX UserLibrary module nodes are now listed, as shown below. The JavaFXLibrary node can be found under the last Libraries node.
(1) Select Tools > Update Center from the main menu of the IDE.
(2) In the Select Location of Modules page, select the NetBeans Update Center Beta check box and unselect all other checkboxes.

(3) Click Next and the wizard checks for any available updates for the plugin.
(4) In the Select Modules to Install page, select the four JavaFX Features nodes and click Add.
The Include in Install pane is updated with the JavaFX modules, as shown below.

(5) Click Next.
(6) Click Accept in the License Agreement dialogs. The Download Modules page appears and progress is shown as the modules are downloaded.

(7) Click Next after the modules have been successfully downloaded.The View Certificate and Install Modules page is displayed list of certificates are made available for your viewing.

(8) Click Finish to proceed with the installation of the JavaFX plugin modules.The IDE proceeds with the installation.
(9) From the main menu, click Tools > Module Manager.The JavaFX Editor, JavaFX Projects, and JavaFX UserLibrary module nodes are now listed, as shown below. The JavaFXLibrary node can be found under the last Libraries node.

(10) Click to dismiss the Module manager.
(11) Proceed to the Getting Started with the JavaFX Script Language tutorial to create your first JavaFX Script program.
2007年10月20日
regexps
"Regular expression" is often shortened to regex or regexp (singular), or regexes, regexps, or regexen (plural).
In computing, a regular expression is a string that is used to describe or match a set of strings, according to certain syntax rules.
Regular expressions are used by many text editors, utilities, and programming languages to search and manipulate text based on patterns. For example, Perl and Tcl have a powerful regular expression engine built directly into their syntax --By Wiki
In computing, a regular expression is a string that is used to describe or match a set of strings, according to certain syntax rules.
Regular expressions are used by many text editors, utilities, and programming languages to search and manipulate text based on patterns. For example, Perl and Tcl have a powerful regular expression engine built directly into their syntax --By Wiki
Intranet(企業網路)
An intranet is a private computer network that uses Internet protocols, network connectivity to securely share part of an organization's information or operations with its employees. --by Wiki
狐狸的故事
有一隻狐狸,在路上閒逛時,眼前忽然出現一個很大的葡萄園,果實纍纍,每顆葡萄看起來都很可口,讓牠垂涎欲滴。
葡萄園的四周圍著鐵欄杆,狐狸想從欄杆的縫隙鑽進園內,卻因身體太胖了,鑽不過去。於是狐狸決定減肥,讓自己瘦下來。
牠在園外餓了三天三夜後,果然變苗條了,真是皇天不負苦心人,終於順利鑽進葡萄園內。
狐狸在園內大快朵頤,葡萄真是又甜又香啊!
不知吃了多久,牠終於心滿意足了。
但當牠想溜出園外時,卻發現自己又因為吃得太胖而鑽不出欄杆,於是只好又在園內餓了三天三夜,瘦得跟原先一樣時,才順利地鑽出園外。
回到外面世界的狐狸,看著園內的葡萄,不禁感嘆:空著肚子進去,又空著肚子出來,真是白忙一場啊!
我起初也以為這個故事告訴我們,人孑然一身來到這世界,又孑然一身的離開這個世界,到頭來還不是白忙一場!呵,這個講故事的人卻說,看問題要看重點。這個故事跟人生一樣,重點是在中間的部份:你看,狐狸在葡萄園內吃得多麼快樂啊!
「即使生命是一場空,也要空得很充實,縱然人生是白忙一場,也要忙得很快樂。」
葡萄園的四周圍著鐵欄杆,狐狸想從欄杆的縫隙鑽進園內,卻因身體太胖了,鑽不過去。於是狐狸決定減肥,讓自己瘦下來。
牠在園外餓了三天三夜後,果然變苗條了,真是皇天不負苦心人,終於順利鑽進葡萄園內。
狐狸在園內大快朵頤,葡萄真是又甜又香啊!
不知吃了多久,牠終於心滿意足了。
但當牠想溜出園外時,卻發現自己又因為吃得太胖而鑽不出欄杆,於是只好又在園內餓了三天三夜,瘦得跟原先一樣時,才順利地鑽出園外。
回到外面世界的狐狸,看著園內的葡萄,不禁感嘆:空著肚子進去,又空著肚子出來,真是白忙一場啊!
我起初也以為這個故事告訴我們,人孑然一身來到這世界,又孑然一身的離開這個世界,到頭來還不是白忙一場!呵,這個講故事的人卻說,看問題要看重點。這個故事跟人生一樣,重點是在中間的部份:你看,狐狸在葡萄園內吃得多麼快樂啊!
「即使生命是一場空,也要空得很充實,縱然人生是白忙一場,也要忙得很快樂。」
利用Axis TCP Monitor 檢視 soap package
將axis.jar複製到 Tomcat 5.5\webapps\Xfire\WEB-INF\lib 目錄下
1)先開啟TCP Monitor 從Dos下改變路徑至Tomcat 5.5\webapps\Xfire\WEB-INF\lib 之下下 Command line :java -classpath axis.jar org.apache.axis.utils.tcpmon =>出現TCP Monitor

2)請在 Listen Port# 的欄位任意輸入一個大於 1024 的整數,例如 9999,然後 click "Add" 鈕,這時候,程式會新增一個 tab,請選擇這個 tab 開始監測 SOAP 訊息。然後就出現畫面,等待連線

3)再另開一個Dos Window 執行自己寫好的Web Service ,我以HelloService.java & IHelloService.java 當例子,再另外寫了HelloServiceClient.java的Client programa)HelloService.java

b)IHelloService.java

c)HelloServiceClient.java

編譯HelloServiceClient.java 並且執行 則可以從TCP Monitor 監測到package ,則可以得到以下結果:

1)先開啟TCP Monitor 從Dos下改變路徑至Tomcat 5.5\webapps\Xfire\WEB-INF\lib 之下下 Command line :java -classpath axis.jar org.apache.axis.utils.tcpmon =>出現TCP Monitor

2)請在 Listen Port# 的欄位任意輸入一個大於 1024 的整數,例如 9999,然後 click "Add" 鈕,這時候,程式會新增一個 tab,請選擇這個 tab 開始監測 SOAP 訊息。然後就出現畫面,等待連線

3)再另開一個Dos Window 執行自己寫好的Web Service ,我以HelloService.java & IHelloService.java 當例子,再另外寫了HelloServiceClient.java的Client programa)HelloService.java

b)IHelloService.java

c)HelloServiceClient.java

編譯HelloServiceClient.java 並且執行 則可以從TCP Monitor 監測到package ,則可以得到以下結果:

Nutch Setup and Use
 Nutch作為一款剛剛誕生的開源Web搜索引擎,提供了除商業搜索引擎外的一種新的選擇。個人、企業都可通過Nutch來構建適合於自身需要的搜索引擎平台,提供適合於自身的搜索服務,而不必完全被動接收商業搜索引擎的各種約束。
Nutch作為一款剛剛誕生的開源Web搜索引擎,提供了除商業搜索引擎外的一種新的選擇。個人、企業都可通過Nutch來構建適合於自身需要的搜索引擎平台,提供適合於自身的搜索服務,而不必完全被動接收商業搜索引擎的各種約束。Nutch的工作流程可以分為兩個大的部分:抓取部分與搜索部分。抓取程序抓取頁面並把抓取回來的資料進行反向索引,搜索程序則對反向索引進行搜索回答使用者的請求,索引是聯系這兩者的紐帶。圖1是對Nutch整個工作流程的描述。
首先需要建立一個空的URL資料庫,並且把起始根urls添加到URL資料庫中(步驟1),依據URL資料庫在新創建的segment中生成fetchlist,存放了待爬行的URLs(步驟2),根據fetchlist從Internet進行相關網頁內容的爬行抓取與下載(步驟3),隨后把這些抓取到的內容解析成文本與資料(步驟4),從中提取出新的網頁連結URL,並對URL資料庫進行更新(步驟5),重復步驟2-5直到達到被指定的爬行抓取深度。以上過程構成了Nutch的整個抓取過程,可以用一個循環來對其進行描述:生成→抓取→更新→循環。
當抓取過程完成后,對抓取到的網頁進行反向索引,對重復的內容與URL進行剔除,然后對多個索引進行合並,為搜索建立統一的索引庫,而后使用者可通過由Tomcat容器提供的Nutch使用者界面提交搜索請求,然后由Lucene對索引庫進行查詢,並返回搜索結果給使用者,完成整個搜索過程。
Nutch程序採用Java語言編寫,其運行環境需要一個Tomcat容器。本文運行環境以最新的j2sdk1.4.2_12及jakarta-tomcat-5.0.28為例。
使用Nutch進行資料抓取
Nutch通過運行網絡爬蟲工具進行網絡內容的抓取,它提供了爬行企業內部網與爬行整個互聯網這兩種方式。
● 爬行企業內部網
爬行企業內部網(Intranet Crawling)這種方式適合於針對一小撮Web服務器,並且網頁數在百萬以內的情況。它使用crawl命令進行網絡爬行抓取。在進行爬行前,需要對Nutch進行一系列的配置,過程如下:
首先,需要創建一個目錄,並且在此目錄中創建包含起始根URLs的文件。我們以爬行搜狐網站(http://www.sohu.com)為例進行講述。
#cd /usr/local/nutch
#mkdir urls
#touch urls/sohu
因此文件urls/sohu的內容為:http://www.sohu.com/。依據爬行網站的實際情況,可繼續在此文件末尾添加其他URL或者在URL目錄里添加其他包含URL的文件。需要注意的是,在Nutch0.7的版中不需要創建目錄,直接創建包含起始根URL的文件即可。
接下來,要編輯conf/crawl-urlfilter.txt文件,將文中MY.DOMAIN.NAME部分替換為準備爬行的域名,並去掉前面的注釋。因此在本文中進行域名替換后的形式為:
+^http://([a-z0-9]*\.)*sohu.com/
文件conf/crawl-urlfilter.txt主要用於限定爬行的URL形式,其中URL的形式使用正則表達式進行描述。
然后,編輯文件conf/nutch-site.xml,並且必須包含以下內容:
< ?xml version="1.0"?>
< ?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
< !-- Put site-specific property overrides in this file. -->
nfiguration>
<>
<>http.agent.name< /name>
<>sohu.com< /value>
<>sohu.com< /description>
< /property>
< /configuration>
除http.agent.name外,在<> < /configuration>間一般還包括http.agent.description、http.agent.url、http.agent.email這三個選項。
最后,開始爬行抓取。完成對Nutch的配置后,運行crawal命令進行爬行。在本文中爬行腳本為:
#bin/nutch crawl urls -dir sohu -depth 5 -topN 1000
其中命令行中各參數項含義分別為:dir指定爬行結果的存放目錄,此處dir為sohu;depth指定從根URL起將要爬行的深度,此例depth設定為5;N設定每一層爬行靠前的N個URL,此例N值設定為1000。另外,crawl還有一個參數項:threads,它設定並行爬行的進程數。在爬行過程中,可通過Nutch日志文件查看爬行的進展狀態,爬行完成后結果存放在sohu目錄里。
● 爬行整個互聯網
爬行整個互聯網(Whole-web crawling)是一種大規模網絡爬行,與第一種爬行方式相對,具有更強的控制性,使用inject、generate、fetch、updatedb等比較低層次的命令,爬行量大,可能需要數台機器數周才能完成。
首先,需要下載一個包含海量URL的文件。下載完成后,將其拷貝到Nutch主目錄,並且解壓縮文件。
wget http://rdf.dmoz.org/rdf/content.rdf.u8.gz
#cd /usr/local/nutch
#cp /home/zyhua/content.rdf.u8.gz .
#gunzip content.rdf.u8.gz
content.rdf.u8包含了約三百萬個URL,在此僅隨機抽取五萬分之一的URL進行爬行。同第一種方法一樣,首先需要建立包含起始根URL的文件及其父目錄。
#mkdir urls
#bin/nutch org.apache.nutch.tools.DmozParser content.rdf.u8 -subset 50000 > urls/urllist
採用Nutch的inject命令將這些URL添加crawldb中。這里,目錄crawl是爬行資料存儲的根目錄。
#bin/nutch inject crawl/crawldb urls
然后,編輯文件conf/nutch-site.xml,內容及方法與“爬行企業內部網”類似,此處略過。接著,開始爬行抓取。可以將整個爬行抓取的命令寫成一個shell腳本,每次抓取只需執行此腳本即可,即生成→抓取→更新的過程。根據需要可反復運行此腳本進行爬行抓取。腳本範例及相應的說明如下:
#!/bin/sh
bin/nutch generate crawl/crawldb crawl/segments
lastseg=`ls -d crawl/segments/2* tail -1`
echo $lastseg
bin/nutch fetch $lastseg
bin/nutch updatedb crawl/crawldb $lastseg
#chmod u+x crawl //使其可執行。
#./crawl //運行腳本開始爬行抓取。
最后,進行索引。爬行抓取完后,需要對抓取回來的內容進行索引,以供搜索查詢。過程如下:
#bin/nutch invertlinks crawl/linkdb crawl/segments/* //倒置所有連結
#bin/nutch index crawl/indexes crawl/crawldb crawl/linkdb crawl/segments/*
使用Nutch進行資料搜索
Nutch為使用者提供了友好的搜索界面,它需要一個servlet容器來提供服務,本文選用了開源的Tomcat容器。首先,將Nutch的war文件部署到Tomcat容器里。
#rm -rf
$CATALINA_HOME/webapps/ROOT*
#cp /usr/local/nutch/nutch*.war $CATALINA_HOME/webapps/ROOT.war
啟動Tomcat,它會自動解開war文件。
#$CATALINA_HOME/bin/catalina.sh start
修改文件nutch-site.xml,指定Nutch的資料存放目錄。增加以下內容到文件nutch-site.xml中。
<>
<>searcher.dir< /name>
<>/usr/local/nutch/sohu< /value>
< /property>
< /configuration>
//在第二種爬行方法中的值為/usr/local/nutch/crawl。
修改server.xml,使輸入中文進行搜索時不出現亂碼現象。將以下內容添加到server.xml文件適當的地方。
URIEncoding=”UTF-8” useBodyEncodingForURI=”true”
配置更改完成后,重啟Tomcat服務器。
#$CATALINA_HOME/bin/catalina.sh stop
#$CATALINA_HOME/bin/catalina.sh start
Nutch的運行維護
隨著Internet上網頁的不斷更新,企業網站數量的不斷增加,需要定期進行爬行抓取,保證搜索結果的準備性與時效性。因此Nutch的運行與維護主要集中在對已有資料的增添與更新上,具體包括了爬行、索引及資料的合並等操作。主要有以下兩種典型情況。
● 重爬行抓取
重爬行抓取的作用主要表現在兩個方面,一方面是對已有內容進行更新,另一方面是發現新的內容。Nutch的Wiki網站提供的重爬行的完整腳本,其連結為:
http://wiki.apache.org/nutch/IntranetRecrawl
該連結提供了Nutch.0.7及Nutch0.8兩種版本的重爬行腳本。將腳本內容保存為文件/usr/local/nutch/bin/recrawl,便可執行,運行腳本進行重爬行。
#chmod u+x bin/recrawl
#/usr/local/nutch/bin/recrawl servlet_path crawl_dir depth adddays [topN]
//請務必使用recrawl的絕對路徑運行此腳本。
recrawl的工作過程包括以下四步:基於“生成→抓取→更新→循環”的資料爬行抓取;segments的合並及無用內容的剔除;重索引及重復內容的剔除;在Tomcat容器中重載應用程序配置。
使用Cron定期進行重爬行抓取,將如下內容添加到文件/etc/crontab末尾重啟Cron即可。
00 01 * * 6 root /usr/local/nutch/bin/recrawl
#每週六凌晨01:00進行重爬行抓取。僅供參考。
● 新增URL后的爬行抓取
主要針對第一種爬行方式,用於解決新增URL時的爬行問題。主要包括以下幾步:對新增URL的爬行抓取;新資料與已有資料的合並;重載應用程序配置。對新增URL的爬行方式與舊URLs的爬行方式相同。Nutch的Wiki網站同樣提供了進行資料合並的腳本代碼,連結為:
http://wiki.apache.org/nutch/MergeCrawl
將其保存為文件/usr/local/nutch/bin/mergecrawl,使可執行,進行資料合並。
#chmod u+x bin/mergecrawl
#bin/mergecrawl merge_dir dir1 dir2 ...
修改$CATALINA_HOME/webapps/ROOT/WEB-INF/classes/nutch-site.xml文件中searcher.dir屬性的值為新目錄名。在Tomcat服務器中重載應用程序配置。
#touch $CATALINA_HOME/webapps/ROOT/WEB-INF/web.xml
Tomcat Server's error logs
error message: WebappClassLoader: validateJarFile(D:\netbank\jsp\WEB-INF\lib\servlet.jar) - jar not loaded. See Servlet Spec 2.3, section 9.7.2. Offending class: javax/servlet/Servlet.class
Solution: 比對一下Tomcat中common\lib\*.jar和應用的.jar日期就知道了,Tomcat中有的,就不要重覆佈署了,删除即可。
Solution: 比對一下Tomcat中common\lib\*.jar和應用的.jar日期就知道了,Tomcat中有的,就不要重覆佈署了,删除即可。
訂閱:
文章 (Atom)

{kind=link}